
本篇文章旨在探讨 GPU(尤其是 NVIDIA H100)的市场供需概况。
本文一经发出便引起了巨大的反响。它登上了 HN、Techmeme 以及多家电子邮件通讯的头版,受到了包括 Andrej Karpathy 在内的一些知名人士的推特评论,来自 Inflection 的 Mustafa(他即将上线 10 亿美元的 GPU)和 Stability 的 Emad 也对其进行了评论。本文提到的歌曲也在《纽约时报》中受到了提及,一些资产管理公司和 AI 公司的创始人还与该歌曲的作者取得了联系。如果您尚未阅读本文,希望您会喜欢!
简介
“AI 热潮被低估的原因之一是 GPU/TPU 的短缺。这种短缺正在对产品发布和模型训练造成各种限制,但这些限制并不容易察觉。相反,我们看到的只是 NVIDIA 价格的飙升。一旦供应能够跟上,AI 将会加速发展。”
—— Adam D’Angelo,Quora & Poe.com CEO,前 Facebook CTO

目前每个人都希望 NVIDIA 能够生产更多的 A/H100 产品。
—— 某云服务商高管
“我们的 GPU 资源非常短缺,所以越少人使用我们的产品越好。”
“我们希望用户减少我们的产品使用频率,因为我们没有足够的 GPU 资源。”
—— Sam Altman,OpenAI CEO
对于 Azure/Microsoft 而言:
-
在 Azure/Microsoft 内部,他们正在对员工使用 GPU 进行速率限制。员工必须排队等待,就像在上世纪 70 年代大学用大型机一样。我认为 OpenAI 目前正在占用所有的 GPU 资源。
-
Coreweave 的交易,似乎是将他们的 GPU 基础设施整合到其他地方的一部分内容。
—— 某匿名人士
-
造成瓶颈的原因是什么(需求有多大?供应有多少?) -
瓶颈问题会持续多长时间。 -
如何解决这一问题?
GPU 之歌
我刚刚看了那个视频,它非常有趣,作者做的很好。
—— Mustafa Suleyman,Inflection AI CEO
对于 H100 GPU 的需求
-
具体而言,什么是人们想买但买不到? -
他们需要多少个这样的 GPU? -
为什么他们不能使用其他型号的 GPU? -
其他产品的名称是什么? -
公司是从哪里购买?什么价格?
“目前似乎有非常多的人都在购买 GPU”。
—— Elon
-
训练 LLM 的初创企业
-
OpenAI(通过 Azure)、Anthropic、Inflection(通过 Azure8 和 CoreWeave9)、Mistral AI
-
CPS(云服务商)
-
三巨头:Azure、GCP 和 AWS -
其他公有云服务商:Oracle -
CoreWeave 和 Lambda 等大型私有云服务商
-
其他大型公司
-
特斯拉
根 据我的分析,以相同的工作负荷运行更便宜。如果你能够找到二手的 V100 图形处理器,那么它是一个非常划算的选择,但实际上你找不到。
—— 某匿名人士
老实说,我对于它是否具有最佳性价比并不确定。在训练方面,A100 和 H100 的性价比看起来差不多。但在推理方面,我们发现 A10G 的性能已经足够,并且价格要便宜得多。
—— 某私有云高管
过去有一段时间,A10G 性能已经足够。但在当前使用大量 Falcon 40b 和 Llama2 70b 的情况下,不再成立,现在我们需要 A100 型号的 GPU。
确切地说,我们需要两个 A100 型号的 GPU。因此,在推断任务中,互连速度非常重要。
—— 另一家私有云高管
对于多节点训练,所有的请求都要求使用 A100 或 H100 GPU,并且需要使用 InfiniBand 网络连接。唯一的例外是在进行推理时,工作负载只需要单个 GPU 或单个节点。
—— 某私有云高管
-
内存带宽; -
FLOPS (tensor cores 或等效的矩阵乘法单元) -
高速缓存和高速缓存延迟 -
诸如 FP8 计算能力等额外功能 -
计算性能(与 CUDA 核心数量相关) -
互连速度(如 InfiniBand)
H100 GPU 更受青睐,因为它的效率高出 3 倍多,但成本仅增加 1.5-2 倍。结合整个系统的成本来看,H100 GPU / 美元性能表现更出色(可能是 4-5 倍)。
—— 某深度学习研究员
由于网络限制和不可靠的硬件,AWS 难以使用。主要问题在于网络和可靠的数据中心。
—— 某深度学习研究者
我不会说这是非常关键的,但它确实会影响性能。我猜这取决于瓶颈所在。对于某些架构或软件实现,瓶颈不一定在网络,但如果在网络上,GPUDirect 可以提升 10-20% 的性能,对于昂贵的训练任务来说,这是相当显著的提升。
话虽如此,现在 GPUDirect RDMA 已经非常普遍,几乎可以默认支持。我认为对于非 InfiniBand 网络的支持可能不那么强大,但大多数为神经网络训练优化的 GPU 集群都配备了 InfiniBand 网络和网卡。对性能来说更大的因素可能是 NVLink,因为它比 InfiniBand 更罕见,但只有在采用特定的并行化策略时才显得至关重要。
因此,像强大的网络和 GPUDirect 这样的功能可以让您更轻松,可以保证软件在初始状态下性能更好。但如果更关心成本或正在使用的基础设施,这并不是严格的要求。
—— 某深度学习研究员
我怀疑 2 个月的时间差可能被高估了,很可能并不具有实际意义。
—— 某 ML 工程师
谁会愿意承担部署 10,000 个 AMD GPU 或 10,000 个未经充分验证的初创公司硅芯片的风险呢?这毕竟是一项价值近 3 亿美元的投资。
——某私有云高管
MosaicML/MI250 – 是否有人向 AMD 询问过可用性?似乎 AMD 没有生产多余 Frontier 项目所需的数量,而现在 TSMC 的 CoWoS 生产能力已被 NVIDIA 占用。MI250 可能是一个可行的替代方案,但目前不可用。
—— 某已退休的半导体行业专业人士
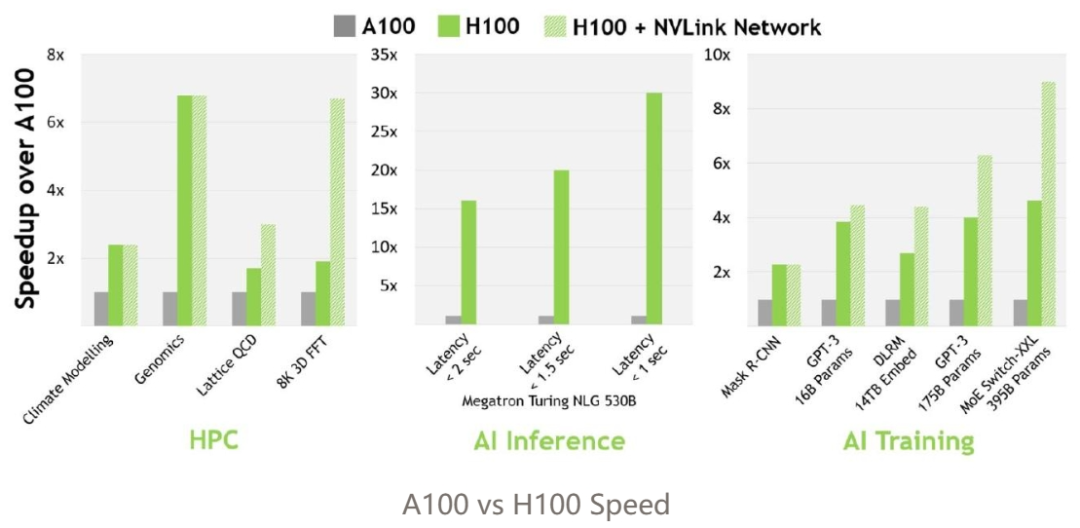
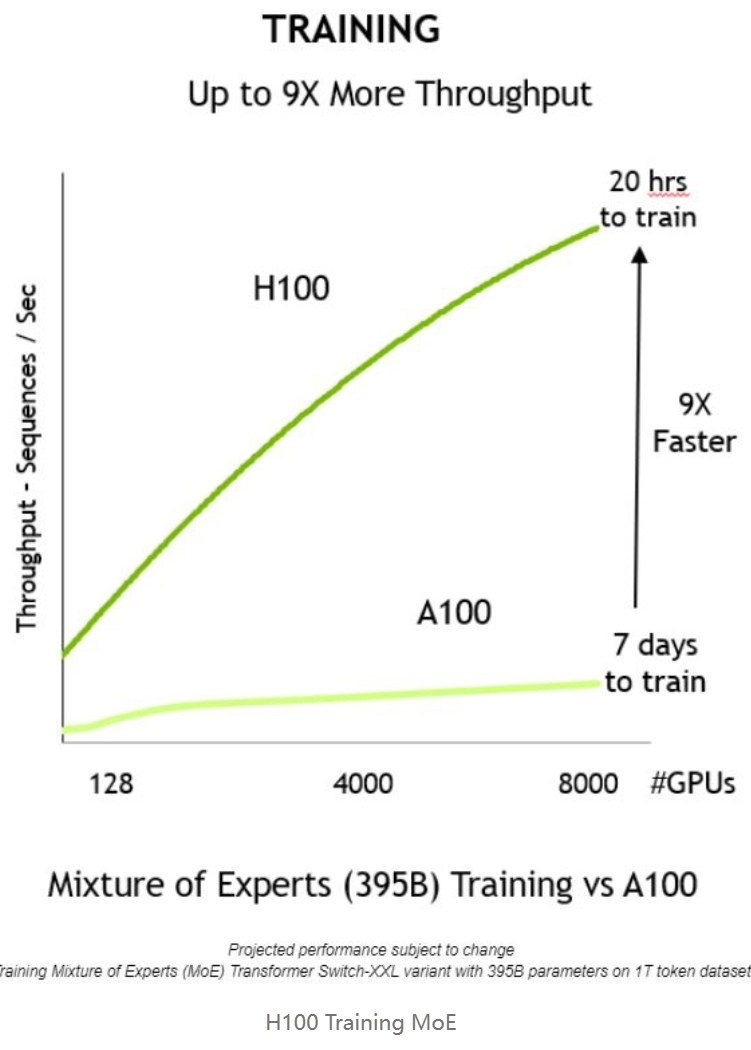
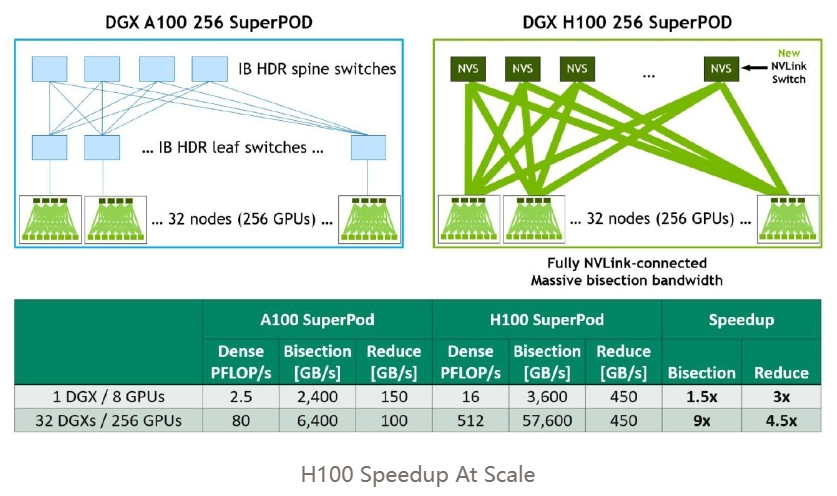
A100 GPU 将在未来几年内成为如今的 V100 GPU。目前,由于性能限制,我不知道有谁在 V100 上进行 LLM 的训练工作,但它们仍然用于推断和其他工作负载。类似地,随着更多的 AI 公司将工作负载转移到 H100 GPU 上,A100 GPU 的价格将会下降,但仍然会有需求,特别是用于推理等。
—— 某私有云高管
我认为也有可能将来有一些筹集了大笔资金的初创公司最终破产,然后会有大量的 A100 GPU 重新流入市场。
—— 另一家私有云高管
不使用 V100 GPU 的主要原因是缺乏 brainfloat16(bfloat16,BF16)数据类型。如果没有这个数据类型,训练模型会变得非常困难。OPT 和 BLOOM 性能差的主要原因可以归因于没有这个数据类型(OPT 是在 float16 中进行训练的,BLOOM 的原型大部分是在 fp16 中完成的,这种数据类型没有达到与在 bf16 中进行的训练相一致的数据通用性)。
-
H100 = 1x H100 GPU -
HGX H100 是 NVIDIA 的推理服务器平台,OEMs 会通过它来构建 4-GPU 或 8 GPU 服务器。这些服务器由第三方 OEM 制造(如 Supermicro)。 -
DGX H100 是 NVIDIA 官方的 H100 服务器,搭载了 8 块 H100 GPU。 NVIDIA 是唯一的供应商。 -
GH200 的配置包括 1 块 H100 GPU 和 1 块 Grace CPU。 -
DGX GH200 的配置包括 256 块 GH200,预计将于 2023 年底推出。 只有 NVIDIA 提供。

-
GPT-4 可能是在大约 10,000 – 25,000 个 A100 GPU 的基础上训练出来的。 -
Meta 大约有 21,000 个 A 100 GPU,Tesla 大约有 7,000 个 A100 GPU,而 Stability AI 大约有 5,000 个 A100 GPU。 -
Falcon-40B 模型是在 384 个 A100 GPU 上训练出来的。 -
Inflection 通过 3,500 块 H100 GPU 来训练他们的 GPT-3.5 等效模型。
H100 GPU 的供应
-
生产方面存在哪些瓶颈? -
哪些组件? -
谁在生产它们?
-
N5
-
4N 在这可以被看作是 N5 的增强版,但在性能和特性上不如 N5P。 -
N5P
-
4N 在这可以被看作是 N5P 的增强版,但在性能和特性上不如 N5。
-
N4 -
N4P
-
金属元素: 这些元素对 GPU 的生产至关重要。它们包括:
-
铜:由于具有高导电性而用于电气连接的制造。 -
钽:由于能保持较高的电荷量,常用于电容器中。 -
金:由于其耐腐蚀性,可用于高品质电镀和连接器。 -
铝:常用于散热器,帮助散热。 -
镍:常用于连接器的涂层,具有耐腐蚀性。 -
锡:用于焊接组件。 -
铟:用于热界面材料,具有良好的导热性。 -
钯:用于某些类型的电容器和半导体器件。
-
硅(类金属): 制造半导体器件的主要材料。 -
稀土元素: 这些元素因其独特的性质而被用于 GPU 的各个部分。 -
其他金属和化学品: 这些材料用于生产的各个阶段,从制造硅晶片到 GPU 最终组装。 -
基板: 这是安装 GPU 组件的材料。 -
封装材料: 用于容纳和保护 GPU 芯片。 -
焊球和焊线: 用于连接 GPU 芯片与基板和其他元件。 -
被动元件: 包括电容器和电阻器,它们对 GPU 的运行至关重要。 -
印刷电路板(PCB): 这是安装 GPU 所有元件的电路板,它提供了元件之间的电连接。 -
热化合物: 用于改善芯片与散热器之间的热传导。 -
半导体制造设备: 包括光刻机、蚀刻设备、离子注入设备等。 -
无尘室设施: 这是 GPU 生产过程中的必需设施,以防止硅晶片和其他组件的污染。 -
测试和质量控制设备: 用于确保 GPU 符合所需的性能和可靠性标准。 -
软件和固件: 这些对于控制 GPU 的运行以及与计算机系统的其他部分连接至关重要。 -
包装和运输材料: 这些是将最终产品完好无损地交付给客户所必需的。 -
软件工具: 用于 CAD 和仿真的软件工具在设计 GPU 的结构和测试功能方面至关重要。 -
能源消耗: 在 GPU 芯片的制造过程中,由于需要使用高精度的机械设备,因此需要大量电力。 -
废物管理: GPU 在生产过程会产生废弃物,必须妥善管理和处理,因为所使用的许多材料可能对环境有害。 -
测试能力: 用于验证功能和性能的定制 / 特殊测试设备。 -
芯片封装: 将硅晶片组装成可用于更大系统的元件封装。
展望与预测
采购 H100
-
网络(AWS 和 Google Cloud 在采用 InfiniBand 方面较慢,因为它们有自己的方法,尽管大多数寻找大规模 A100/H100 集群的初创公司都在寻求 InfiniBand)。 -
可用性(Azure 的 H100 主要供应给 OpenAI。GCP 在获取 H100 方面有一定困难。)
-
OpenAI: Azure。 -
Inflection: Azure 和 CoreWeave。 -
Anthropic: AWS 和 Google Cloud。 -
Cohere: AWS 和 Google Cloud。 -
Hugging Face: AWS。 -
Stability AI: CoreWeave 和 AWS。 -
Character.ai: Google Cloud。 -
X.ai: Oracle。 -
NVIDIA: Azure。
结束语
-
用户喜欢 ChatGPT,它可能创造了 5 亿多美元的年收入。 -
ChatGPT 在 GPT-4 和 GPT-3.5 API 上运行。 -
GPT-4 和 GPT-3.5 API 需要 GPU 才能运行,并且需要大量的 GPU。OpenAI 希望为 ChatGPT 和它们的 API 发布更多的功能,但他们做不到,因为他们没有足够的 GPU。 -
他们通过微软 / Azure 购买了大量 NVIDIA GPU。具体来说,他们最想要的 GPU 是 NVIDIA H100 GPU。 -
为了制造 H100 SXM GPU,NVIDIA 使用台积电进行制造,并使用台积电的 CoWoS 封装技术,同时主要使用 SK Hynix 的 HBM3。
-
公司高管或创始人意识到在 AI 领域存在巨大的机遇。也许他们是一家企业,想要利用自己的数据来训练一个 LLM,然后在外部使用它或出售访问权;也许他们是一家初创公司,希望建立一个 LLM 并销售。 -
他们知道自己需要 GPU 来训练大型模型。 -
他们与来自大型云服务商(Azure、Google Cloud、AWS)的一些人进行了交流,试图获得许多 H100。 -
他们发现无法从大型云服务商那里获得足够的资源分配,并且有些服务商的网络配置也不理想。因此,他们开始与其他服务商洽谈,如 CoreWeave、Oracle、Lambda、FluidStack。如果他们想自己购买 GPU,也许他们还会与 OEM 和 NVIDIA 等公司进行讨论。 -
最终,他们获得了大量 GPU。 -
现在,他们尝试达到 PMF。 -
需要注意的是,这条路并不好走 —— 请记住,OpenAI 在较小的模型上实现了 PMF,然后扩大了规模。但是,现在要想达到 PMF,你必须比 OpenAI 的模型在用户使用方面更出色, 因此,为了达到这个目标,你需要一开始就使用比 OpenAI 更多的 GPU。

ccc