摘要
高性能互连网络在高性能计算机系统中扮演着关键角色,对于各节点之间的高速、协同和并行计算至关重要。其性能和可扩展性直接影响整个系统的表现和可扩展性。随着高性能计算机系统性能的不断提升,高性能互连网络的发展趋势主要体现在网络规模和网络带宽的提升上。随着摩尔定律的减缓,为实现高性能计算,互连网络需要采用新的封装设计技术。本文分析了 2021 年 11 月 Top500 榜单中高性能计算机系统所采用的主要互连网络,并详细阐述了一些具有代表性和最先进的高性能互连网络设计,包括 NVIDIA InfiniBand、Intel Omni-Path、Cray Slingshot/Aries,以及一些定制或专有网络,如 Fugaku Tofu、Bull BXI、TH Express 等。同时,全面讨论了该领域的最新技术和发展趋势。此外,通过分析高性能互连网络在后摩尔时代和异构计算时代所面临的挑战,本文提出了对高性能互连网络的展望。
1. 介绍
高性能互连网络(ICN)是高性能计算机系统(HPC)不可或缺的组成部分,其性能直接影响 HPC 上并行运行的效率。随着超级计算机系统性能的不断提升,高性能计算机集成的计算核心数量持续增加1,计算节点的性能也在不断提升。随着高性能计算机系统互连网络规模的不断扩大,大规模互连网络的可扩展性将不可避免地成为限制 HPC 整体性能提升的关键。ICN 的发展趋势主要体现在网络规模和网络带宽的增加上。随着摩尔定律所描述的发展逐渐放缓,采用新的封装和设计技术对高性能互连网络进行改进以实现在 E 级超算计算机时代的高性能计算是必要的。
本文分析了 Top500 榜单中 HPC 使用的互连网络2(ICN),并深入探讨了目前 ICN 领域最具代表性的网络,全面展示了 ICN 领域的最新技术和趋势。此外,通过对后摩尔时代和异构计算时代 ICN 设计面临的挑战的分析,我们对 ICN 的未来进行了预测。
2. 高性能互连网络的背景和研究现状
ICN 可根据多种参数进行分类和特征描述,其中主要的性能特性包括网络带宽、时延、交换机基数(switch radix)和网络拓扑3。带宽表示在一定时间内可以传输的数据量,时延是指数据包从源节点传输到目标节点所需的时间,而交换机基数则指交换机连接到其他节点的端口数量。当前的互连网络正朝着高基数(radix)网络的方向发展,即单个路由器芯片集成的网络端口数量不断增加。从最初的 8 个端口逐渐增加到 16 个、24 个、36 个、48 个,甚至 64 个端口。选择 ICN 拓扑结构主要受节点性能和互连技术的影响。当节点数量较少时,胖树拓扑结构是一个较好的解决方案;而当节点数量较多时,胖树将具有更多的层级、更高的延迟和更高的跳数3。如今,在 Top500 中,最常用的 ICN 拓扑结构包括直连 k-ary n-cubes、胖树、torus 和 mesh,以及 dragonfly。
随着高性能计算性能的不断提升和高性能互连网络技术的迅速发展,各大厂商正在逐步推出基于 56 Gbps 串行器/解串器(SerDes)和 400 Gbps 端口带宽的产品。在 Top500 中,典型的 ICN 包括:InfiniBand 互联4、Slingshot/Aries 互联5,6、Omni-Path 互联7、以太网(包括 Tofu8–10、Sunway11、TH Express12–14、BXI15)以及其他定制或专有互联。国际上,ICN 服务商主要包括美国的 Mellanox(2019 年被 NVIDIA 收购)、英特尔、Cray(2019 年被 HPE 收购)和日本的富士通。中国也拥有高性能互连网络,包括 TH Express 和 Sunway。
从国际高性能计算排名 Top500 可以看出,未来的 HPC 系统不仅将是高性能计算的主体,还将是承载人工智能和大数据分析的主体16。越来越多的高性能计算中心开始使用人工智能,这也反映出用户在不断接受 NVIDIA 的人工智能、加速计算和网络技术,以运行其科学和商业工作负载。尽管在 Top500 中有越来越多的系统同时进行 HPC 和 AI 工作,但 Top10 系统和 Top100 中的大部分系统主要从事传统的 HPC 工作。本文首先将分析在 Top500 中从事传统高性能计算(HPC)工作的系统所使用的互连网络。图 1 显示了截至 2021 年 11 月全球 Top500 排名中 Top10(图 1a)和 Top100(图 1b)系统的互联分布情况。
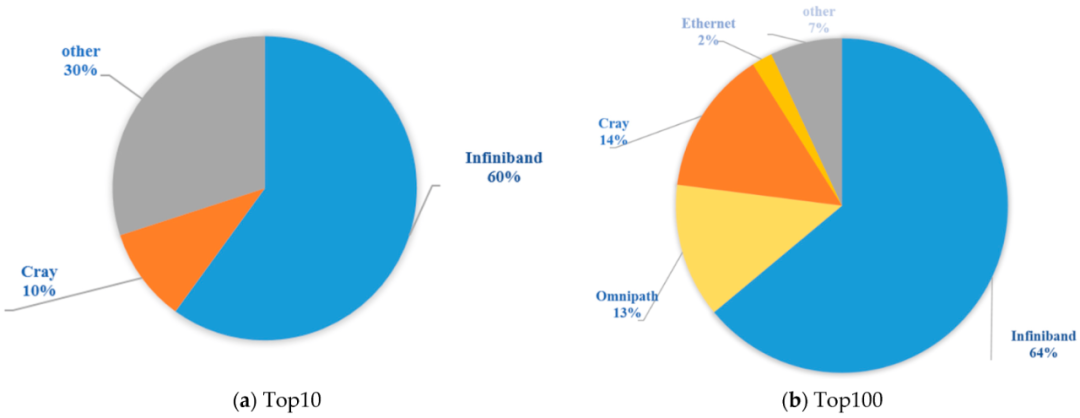
从图 1 可见,Top10 系统的高性能互连网络包括 NVIDIA 的 InfiniBand 互连网络(60%)、Cray 的 Slingshot 互连网络(10%)以及其他定制/专有互连网络,如 Tofu D、Sunway 和 TH Express(30%)。排名第一的 Fugaku 使用的是独立定制的 Tofu D 互连网络,而排名第五的 Taihu Light 采用了独立定制的 Sunway 互连网络。排名第七的 Tianhe 2 A 使用的是独立定制互连网络 TH Express-2。排名第二的 Summit 和排名第三的 Sierra 使用的是 Mellanox EDR InfiniBand。相比之下,排名第六的 Selene、排名第八的 JUWELS Booster Module、排名第九的 HPC5 和排名第十的 Voyager-EUS2 使用的都是 Mellanox HDR InfiniBand。第五名的 Perlmutter 采用 Cray 的定制互连网络 Slingshot-10。在 Top10 和 Top100 中,互连网络的比例保持不变,高性能互连网络的分布如下:InfiniBand(64%)、Cray(14%)、Omni-Path(13%)、其他互连网络,包括 Tofu D、Sunway、TH Express、BXI 和其他定制或专有互连网络(7%);以及 25 Gbps 以上的以太网(2%)。
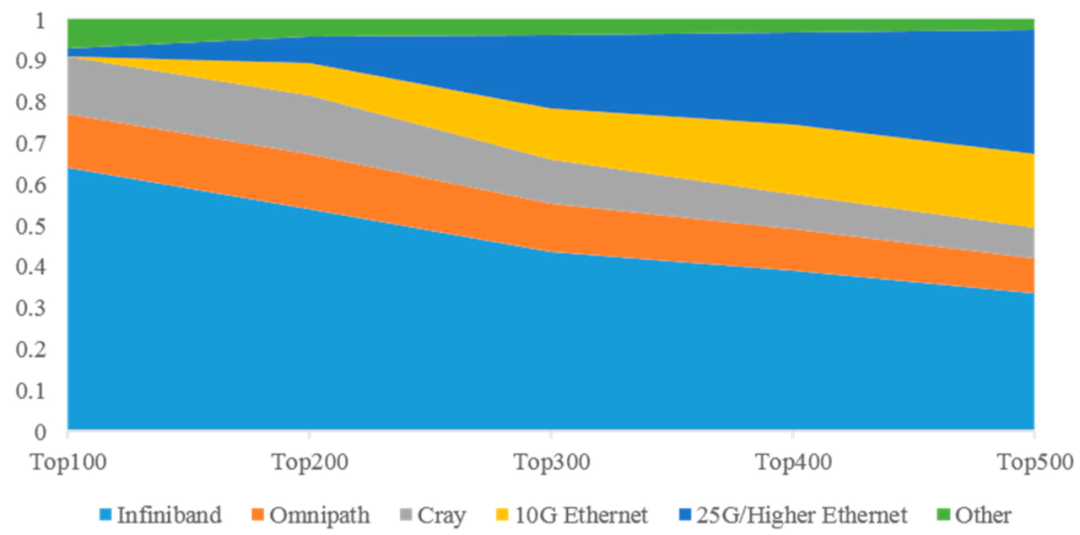
图 2 展示了从 Top100 扩展到 Top500 时高性能计算机系统的互连分布趋势。可以观察到,随着统计系统数量的增加,以太网在 Top500 中的普及率也在不断提高。由于许多学术和工业 HPC 系统无法负担 InfiniBand,或者出于政治或商业原因不愿舍弃以太网,作为服务商、云构建者和 HPC,他们会在集群的一小部分上运行 Linpack。在 Top500 榜单的下半部分,相对较慢的 10 Gbps 以太网非常受欢迎。在 2021 年的榜单中,与以太网互连的超级计算机数量达到了 240 台,占总数的近 50%。InfiniBand 在 Top500 榜单下半部分的比例有所下降,其渗透率从 Top100 的 64% 减少到整个 Top500 的 34%。造成这一现象的原因在于以太网性能的不断提高和以太网价格的不断降低。最新一代的以太网交换机和网卡还包括远程直接内存访问(RDMA)和智能网络布置等重要功能,使以太网相较于传统的 InfiniBand 更具吸引力16。
根据 Top500 榜单的统计数据,支持高性能计算(HPC)、人工智能(AI)和大数据的高性能计算机系统逐渐成为主流。未来,HPC 系统不仅将实现高性能计算,还将承载 AI 和大数据分析。截至 2021 年 11 月,Top10 系统中新增了两个“超级计算云”,可同时满足 AI、HPC 和云计算需求,标志着 HPC 正在加速与 AI 和云计算的融合。在 Top10 系统中,有 8 个系统采用了 NVIDIA 技术提供的加速,而 Top500 系统中有 342 个系统采用 NVIDIA 技术提供加速,其中包括 70% 的新系统。越来越多的 HPC 中心开始使用 AI,这也反映了用户继续采用 NVIDIA 的 AI、加速计算和网络技术来运行科学和商业工作负载的趋势。自 2020 年 11 月以来,使用 InfiniBand 的上榜系统数量增加了 20%16。随着人工智能、HPC 和云计算对低延迟和加速的需求不断增加,InfiniBand 已成为 Top500 的首选网络。
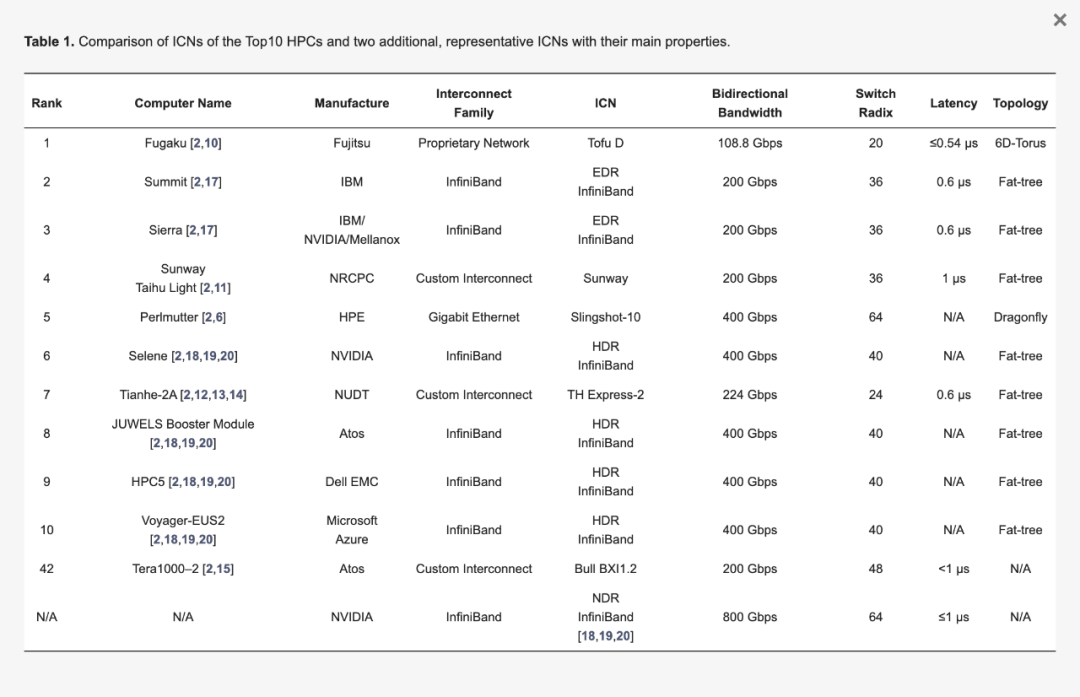
表 1 总结了 2021 年 11 月 Top10 榜单上的主要互连网络性能以及其他两个代表性的互连网络,包括制造商、互连技术、双向带宽、交换机基数、时延和拓扑结构。”N/A”表示未在公开报告中找到精确数据。
本文将在接下来根据 Top500 采用的典型高性能互连技术,介绍互连技术的当前发展状况。
2.1 InfiniBand ICN
在高性能计算领域,由 NVIDIA 提供的 InfiniBand 互连是目前规模最大的互连网络。截至 2021 年 11 月,Top500 系统中有 33.6% 采用 InfiniBand 互连。在 Top10 系统中,第二名的 Summit 和第三名的 Sierra 使用的是 Mellanox EDR InfiniBand,而第六名的 Selene、第八名的 JUWELS Booster Module、第九名的 HPC5 和第十名的 Voyager-EUS2 使用的是 Mellanox HDR InfiniBand。
InfiniBand 互连架构4采用高速互连技术构建了一个完整的系统,用于连接处理器节点。该互连系统独立于主机操作系统和处理器平台。InfiniBand 的最大特点是支持通信功能的卸载。它采用可靠的消息传输和 RDMA 传输来实现模块、帧和机柜之间的互连。同时,InfiniBand 还具备实现不同制造商、不同时代的 InfiniBand 设备互操作性管理的能力,并提供接口来实现各种行业标准的管理功能。
作为商用互连网络的代表,InfiniBand 将高速 SerDes 带宽作为其代际特征18。经过 Quad Data Rate (QDR)、Fourteen Data Rate (FDR)、Enhanced Data Rate (EDR)、High Data Rate (HDR)和 Next Data Rate (NDR)等几代发展后,InfiniBand 持续朝着高端方向发展,支持 40 Gbps、56 Gbps、100 Gbps、200 Gbps 和 400 Gbps 的网络。目前,HDR 已经成为 InfiniBand 互连网络设计的主流配置。HDR 标准的单链速率为 50 Gbps、单端口带宽为 200 Gbps,能够满足当前主流异构高性能计算互连网络的带宽需求。根据 2021 年 11 月的 Top500 统计,Top10 系统中有 4 个使用了 InfiniBand HDR 互连。不过,未来 HPC 可能会需要更高标准的互连技术,例如将 SerDes 标准升级到 NDR,甚至更高。最新的主机通道适配器(HCA)ConnectX-7 和交换机 Quantum-2 已经支持 NDR InfiniBand 400 Gbps 互连18–20。
在主机通道适配器方面,NVIDIA ConnectX-7 提供超低延迟、400 Gbps 的吞吐量,并搭载创新的 NVIDIA 网内计算引擎,以满足 HPC、AI 和超大规模云数据中心对加速、可扩展性和丰富功能技术的需求。该适配器支持单端口或双端口的 400 Gbps 或 200 Gbps(使用八芯小型插拔光模块(OSFP)连接器),以及双端口 200 Gbps(采用四进制小型可插拔(QSFP)连接器)19。它兼容 PCIe 5.0 × 32、PCIe ×1、×2、×4、×8 和 ×16 配置,信息传输速率可达 330-370 Mps,适用于最苛刻的数据中心应用,提供最强大、最灵活的解决方案。此外,ConnectX-7 还改进了 Mellanox 的 Multi-Host技术,支持最多连接四个主机19。
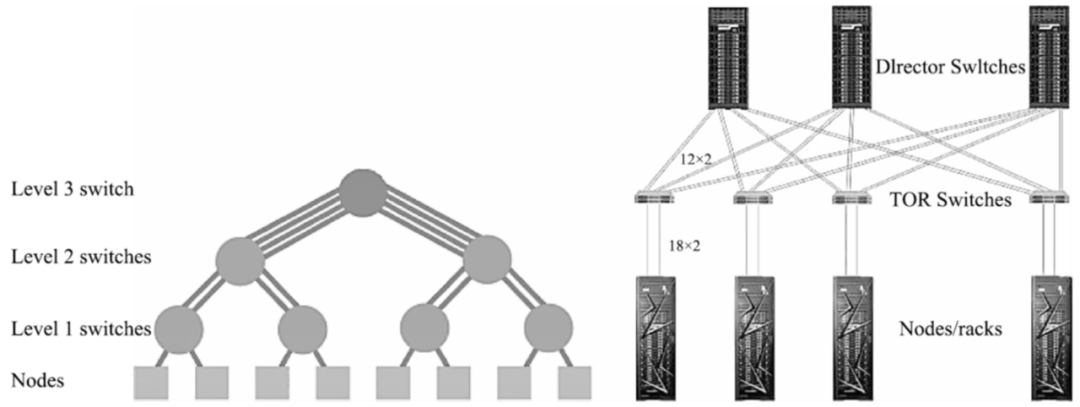
如图 3 所示21,Summit(排名第 2)和 Sierra(排名第 3)在 fat-tree 网络拓扑中使用 EDR InfiniBand 互连。与传统的 fat-tree 拓扑结构不同,Sierra 的互连网络通过 2:1 的缩减比例来减小 fat-tree,其中叶节点交换器和 TOR 交换机的带宽采用 1:2 的缩减比例。TOR(机架顶部)交换机和叶节点交换器均使用 Mellanox EDR InfiniBand 交换设备,该设备有 36 个端口,单端口带宽为 100 Gbps。EDR InfiniBand 提供自适应路由以提高数据传输速度,更好地满足大数据和 AI 的需求。同时,它还提供 NVMe(非易失性内存表达)爆发式访问加速,减少 CPU 在访问 NVMe 时的参与,降低对 CPU 的干扰。Fat-tree 网络通过隔离计算分区和存储子系统之间的流量,提供了更可预测的应用性能。此外,该网络具有高度冗余性和重新配置能力,可确保在网络组件出现故障时仍能提供可靠的高性能17。这种互连能够高效支持上层 MPI 通信软件库,同时实现大规模的进程间通信。
Top10 中的四台机器分别是 Selene(排名第 6)、JUWELS Booster Module(排名第 8)22、HPC5(排名第 9)和 Voyager-EUS2(排名第 10),它们均采用了 200 Gbps 的 HDR InfiniBand 互连。这些节点之间通过 fat-tree 拓扑结构相互连接,并结合了 NVIDIA 最新的节点间通信加速技术,即可扩展的分层汇聚和归约协议(SHARP)2.0。这一技术实现了硬件加速的远程直接内存访问(RDMA)和 MPI 聚合通信处理,通过确保足够的网络带宽,成功降低了节点之间的通信延迟,提高了大规模计算处理的效率。JUWELS Booster 由 936 个计算节点组成,每个节点搭载 4 个 NVIDIA A100 GPU。JUWELS Booster 的 InfiniBand 网络采用了 dragonfly + 网络的实现方式。总共 48 个节点组成一个交换组(cell),在完全的 fat-tree 拓扑中以两级结构相互连接,包括 10 个叶子交换机和 10 个脊椎交换机。系统提供了总共 40 Tbps 的双向带宽。在每个 JUWELS Booster 单元中的 48 个节点内,包含 10 个一级交换机和 10 个二级交换机。为了保持可读性,只展示了总链接量的一小部分。每个二级交换机的第 20 个链接表示与 JUWELS 集群的连接,而其他 19 个外向的二级链接连接到其他单元23。
截至 2021 年 11 月的 Top500 榜单显示,越来越多的高性能计算中心在其系统中引入了人工智能(AI)。这反映了用户持续采用 NVIDIA 的 AI、加速计算和网络技术的组合,以运行科学和商业工作负载。在 Top500 的互连中,InfiniBand 的份额占 34%,共有 168 个系统采用了这一技术。与 2020 年 11 月相比,使用 InfiniBand 的系统数量增加了 20%,而 Mellanox Spectrum 和 Spectrum-2 的数量上升相对较小,为 148 个系统。这使得 NVIDIA 在 Top500 的互连中占据了 63.2% 的市场份额16。这一情况将 InfiniBand 用户和许多以太网用户聚集在 Top500 中,这在一定程度上解释了 NVIDIA 为何愿意投资 69 亿美元收购 Mellanox。随着人工智能、高性能计算和模拟数据对低延迟和加速的需求不断增加,InfiniBand 已成为 Top500 系统的首选网络。
2.2 Omni-Path ICN
在高性能计算领域,英特尔的 Omni-Path 互连是第二大活跃互连网络。在 Top500 榜单上,有 8.4% 的系统采用了英特尔的 Omni-Path 互连,其中包括排名第 23 的 SuperMUC-NG 系统。
2015 年,英特尔发布了 Omni-Path Architecture(OPA)规范7。Omni-Path 是英特尔在前两代 Xeon 可扩展处理器中引入的新功能,直接借鉴了 Cray 的 Aries24和英特尔的 True Scale25架构。True Scale 利用了 InfiniBand 架构26,而 Intel OPA 则通过借鉴高性能计算互连的最佳实践来增强这些能力。其中的创新包括提供可扩展、开放、高性能的 API 框架,称为 Performance Scaled Messaging,以及最近引入的 OpenFabrics Alliance 的 Open Fabrics Initiative,该框架有助于在不断发展的高性能计算中间件和主机布线接口(HFI)硬件 / 软件接口之间创建低阻抗接口27。在第一代 HFI 中,这导致了低延迟、高带宽的实现,其中部分 fabric 协议在处理器 CPU 上执行,利用其多核处理、内存和缓存资源,即所谓的“onload 模型”。另一方面,创新还包括服务级别和服务通道扩展对虚拟通道抽象的支持,从而使得 HFI 和交换机资源的分配更加高效。此外,在网络栈中的链路传输协议层允许高优先级数据包抢占低优先级数据包,使得使用扩展的最大传输单元大小(8K)进行高效的批量传输成为可能,同时减少了在紧密耦合的 MPI 通信中出现的延迟抖动7。
由于许多网络特性集成到 CPU 中,Omni-Path 可以为特定的 Xeon 处理器同构超级计算带来超高的处理器互连性能。OPA 的主要设计目标包括在保证性能的同时降低互连成本和功耗,提高互连密度,增强节点带宽,减少通信延迟,提高 MPI 消息速率,增强可伸缩性,加强系统纠错能力,并提供更高的服务质量。图 4 展示了 OPA 的组件,包括网络卡、交换机和网络管理器7。网络卡用于将计算 / 服务 / 管理节点连接到网络,这些节点可以分配到一个或多个分区。通过网络拓扑,交换机将多个节点构建成一个网络。网络管理器用于集中管理和监视网络。该结构基于互连的交换机组件,具有可扩展的结构。与 InfiniBand 的设计理念不同,OPA 没有过多的卸载实现,许多工作由处理器内核共享。
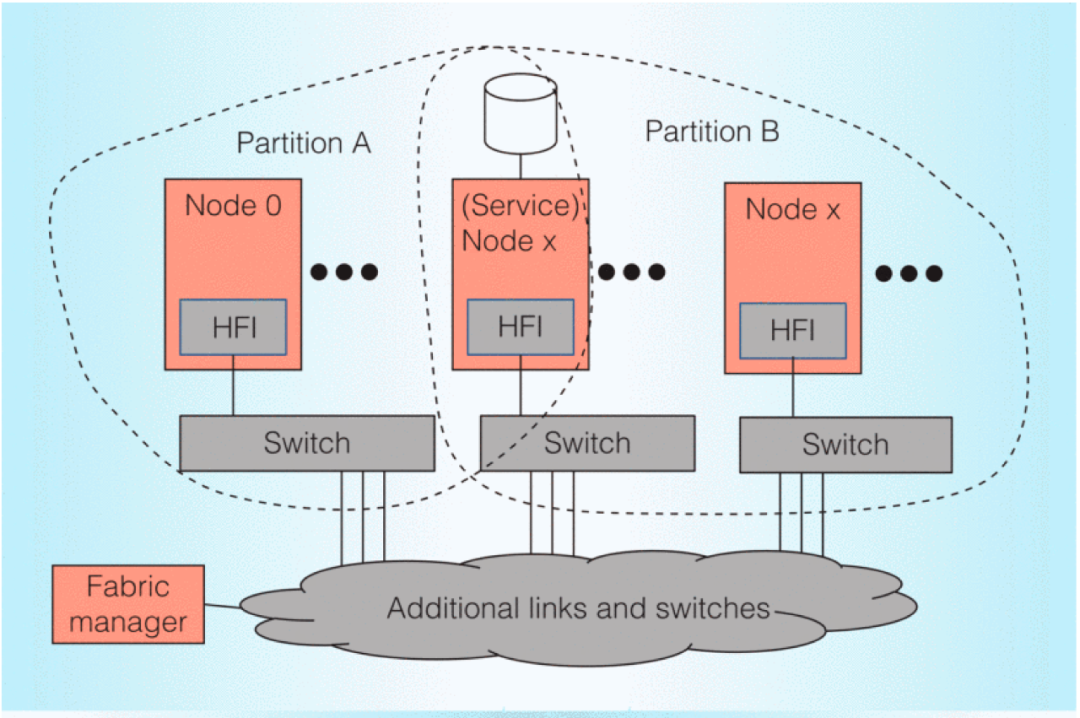
OPA 的第一代产品28支持单端口 100 Gbps EDR 标准,部分兼容 InfiniBand 上层协议,同时支持以太网和存储协议的扩展。第一代主机组网接口代号为 WFR(Wolf River),网络交换芯片的代号为 PRR(Prairie River)。网络接口芯片 WFR 支持单端口 100 Gbps EDR 标准,提供两个 EDR 端口。每个端口在主机端使用 PCle3.0×16,可实现 160 Mps 的消息速率。网络交换芯片 PRR 提供 48 个 EDR 端口,消息交换速率约为 195 M,延迟约为 100~110 纳秒。为追求最终的延迟性能,该芯片放弃了前向纠错功能,在链路层通过重传实现纠错。虽然在 25 Gbps 速率的世代中可接受,但对于 50 Gbps 网络则无法胜任。
由于用户需要购买特定的处理器型号、主板型号和专用交换机,Omni-Path 最终未能在更广泛的市场中获得认可。2019 年底,Intel 宣布停止下一代 Omni-Path 的开发,最终取消了 Omni-Path 产品线。然而,Cornelis 在 2021 年 7 月收购了 IP 并继续开发。Omni-Path 架构正寻求以独立、高性能的互连解决方案的形式卷土重来29。Cornelis 正在对 OPA100 产品进行重大升级,被称为 Omni-Path Express(OPX)。Omni-Path Express 的目标是在高性能计算互连市场中赢得性价比之战30。Cornelis Networks 提供面向 HPC、高性能数据分析(HPDA)和 AI 的高性能互连解决方案。目前,Cornelis 仍在销售由英特尔开发的 Omni-Path 100 Gbps (OPA100) 产品,并计划在 2022 年底推出 400 Gbps 产品,预计将在 2023 年第一季度提供更广泛的选择。OPA400 产品将支持 200 Gbps 的分叉。在 Cornelis Omni-Path 的路线图上,还有更为先进的 800 Gbps 解决方案29。
2.3 Cray ICN Top500 中使用的第三大互连网络是由 Cray 提供的一系列网络,占 Top500 的 7.4%,其中包括第五名的 “Perlmutter” 系统。Cray 的互连产品包括 Seastar31、Gemini32、Aries33,34,以及最新一代的高性能网络互连技术 Slingshot35。在 Top100 中,Cray 的互连不仅包括第一台采用 Slingshot 技术的 “Perlmutter” 机器,还包括多台使用上一代 “Aries” 互连技术的机器。截至 2021 年 11 月,Top100 中有五台 Slingshot 机器和九台 Aries 机器。值得注意的是,美国宣布的下一代异构超级计算机(EI Capitan、Frontier 和 Aurora)都将采用 Slingshot 互连技术。
Gemini 是 Cray 高性能计算机的第二代互连技术,继承了 Seastar 原有 Jaguar系统(Cray XT 系列)的高可扩展性互连架构,能够连接多达 10 万个节点32。Gemini 互连技术被应用于 Cray 的新 Jaguar 系统(Cray XK6 系列)、Blue Waters 系统和 Titan。在 Cray 的第三代互连技术 Aries 中,它在高性能计算领域取得广泛应用。Aries 采用了集成架构,将交换和网络接口芯片紧密耦合。每个计算节点可开放 64 个网络接口,从而构建具有超低网络直径的 dragonfly 拓扑。
在 2019 年,Cray 放弃了 Gemini 互连技术,该技术集成了紧密耦合的交换和网络接口芯片的架构,并推出了新一代高性能网络互连技术 Slingshot。Slingshot 是 Cray 的第八个主要高性能互连网络技术,已经使用了五年以上。与以前的互连网络不同,Slingshot 在标准 Ethernet 上构建了高性能互连协议。Cray 将其称为“HPC Ethernet”。Slingshot 将专有的 HPC 网络优势引入了高度互操作性的 Ethernet 标准。简而言之,Slingshot 交换机首先使用标准 Ethernet 协议运行,但当连接的设备支持先进的“HPC Ethernet”功能时,它将尝试协商高级功能,以同时支持 HPC 和基于标准以太网的数据中心。此外,Slingshot 以标准 Ethernet 的通用优势为基础,为基于标准以太网的设备提供支持。
基于 Slingshot 互连技术,Cray 在 2020 年推出了一个名为 Rosetta 的交换芯片,其交换容量高达 12.8 Tbps。该芯片采用了平铺结构,整合了 256 个 56 Gbps SerDes 块,采用脉冲幅度调制(PAM-4)技术,最大端口达到 64200 Gbps。每个交换节点的总带宽可达 25.6 Tbps35。在构建大型系统时,Cray 采用了 Slingshot 拓扑,但 Slingshot 互连同时支持多种拓扑结构,如 dragonfly、flattened butterfly 和 fat-tree。选择 dragonfly 拓扑主要考虑了成本因素,以减少光缆长度和系统成本。据 Cray 声称,系统中高达 90% 的电缆采用廉价的铜缆,而光缆仅占 10%。Slingshot 互连不仅创新了传统的自适应路由算法,还集成了拥塞控制算法。其中,Slingshot 最大的进步在于先进的拥塞控制,能够迅速检测到拥塞情况。由于 Slingshot 互连的底层采用标准的以太网协议,其交换时延与 InfiniBand 网络之间存在一定差距,介于 300-400 纳秒之间,平均交换时延为 350 纳秒,其中仍包含 150 纳秒左右的纠错。这一数值相较于标准以太网的 450 纳秒交换延迟有着显著提升35。

2.4 Tofu ICN
Tofu ICN 是由日本理化学研究所(RIKEN)和富士通公司联合研发的高性能互连网络,主要应用于日本的 K Computer36。
目前,排名第一的 Fu- gaku 采用了名为 Tofu D 的独立定制互连网络。目前在 Top500 中排名第一的 Fugaku 系统采用了 Tofu D 互连,其基础是 K Computer 的 Tofu 网络10,37。Tofu D 互连系统的独特之处在于,通过片上网络(NoC)架构,整合多核处理器、Tofu 网络路由模块以及 PCle 控制系统,组成 CPU 计算核心 A64FX。
图 710展示了 A64FX 计算节点的框架图。A64FX 结构包括 4 个 CMG(核心存储器组)、六个 TNI(Tofu 网络接口)以及一个搭载有 20 个 28 Gbps 数据速率端口的 Tofu 网络路由器,采用基于 6D-Torus 的 Tofu-D 片上 ICN。每个 CMG 包含 12 个计算核心和 1 个辅助核心,图中每个核心都以“c”标记。物理 6D 网络中的节点地址由六维坐标 X、Y、Z、A、B 和 C 表示,其中 A 和 C 坐标可为 0 或 1,B 坐标可为 0、1 或 2。X、Y 和 Z 坐标的范围取决于系统的大小。当 1 轴上的两个节点坐标相差 1,在其他 5 轴上相同时,它们被视为“相邻”并相互连接。当某个轴被配置为环状时,轴上坐标为 0 的节点与具有最大坐标值的节点相互连接。轴 A 和 C 被固定为网格配置,轴 B 被固定为环状配置。每个节点对 6D 网格 / 环状网络有 10 个端口,其中轴 X、Y、Z 和 B 各使用两个端口,轴 A 和 C 各使用一个端口38。为了为每个 6 个平面提供 54.4 Gbps 的链路带宽,总共提供了 22 个 28.06 Gbps 配置环形网络端口10。
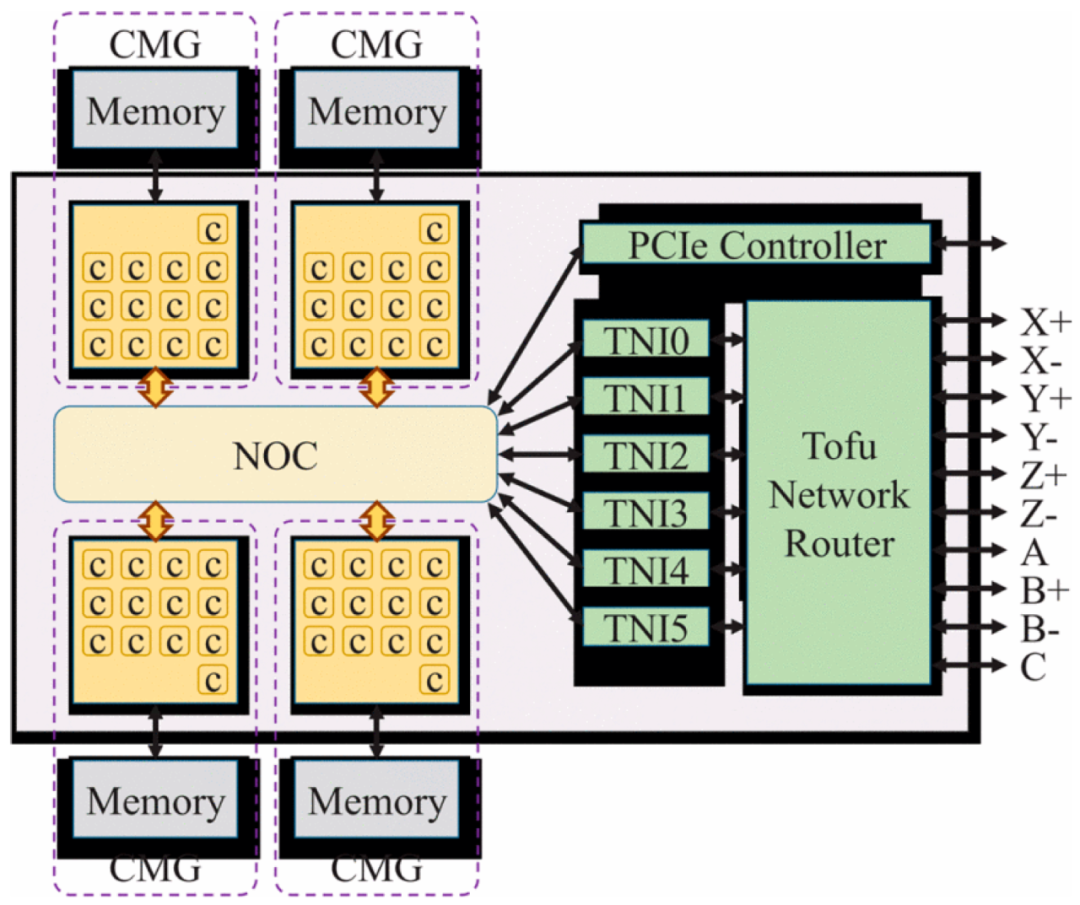
与上一代 K 系统相比,当前系统的传输速率提高了 80%。在虚拟的 3D Torus中,每个节点包含 6 个相邻节点,因此拓扑感知算法可以同时高效利用 6 条通信链路。每个节点的数据注入带宽达到 326.4 Gbps,提供 490 纳秒的单向传输延迟。每个处理器的 I/O 采用 PCle Gen3×16 与外部设备连接。A64FX 的系统架构将网络交换设备与 CPU 紧密集成在一起,有效地缩短了从计算单元到 I/O 的传输延迟,从而有效降低了 I/O 延迟,但也会增加 IC 工艺的复杂性。此外,Tofu D 互连还提供了 Tofu Barrier 的卸载引擎,可在无需 CPU 干预的情况下执行聚合通信操作。
2.5 THExpress/Sunway ICN
目前,中国的高性能计算机主要有 Dawning、Sun- way 和 Tianhe。其中,Dawning E 级超算计算机采用了 200 GB 的 6D 环状网络,而 Sunway 和 Tianhe 则使用了定制的网络芯片38。
Tianhe 高性能计算机系统采用了由国防科技大学研发的 TH Express ICN12-14。TH Express 由两块 ASIC 芯片组成。一块是网络接口芯片(NIC),通过主机接口将系统中的各个节点连接到网络上,并为各种系统和应用软件提供通信服务。另一块是网络路由器芯片(NRC),通过互连拓扑和交换网络连接整个系统。Tianhe E 级超算计算机系统由 512 个节点组成,单个节点的网络带宽达到 400 Gbps。节点通过图 7 中显示的多维度 fat tree 网络拓扑相互连接,可支持 10 万个网络节点,节点之间的通信最大跳数不超过 5 次12。
Sunway 超级计算机由国家并行计算机工程技术研究中心研发,该中心自 2001 年以来一直在研究 InfiniBand 互连技术。Sunway 超级计算机先后推出了 SW-HCA 卡、SW-Switch、完整的 SW-IB 网络管理软件和 InfiniBand 高级应用软件,并基于 IBA 互连技术推出了多个商用集群系统39。Sunway E 级超算计算机由多个超级节点组成,每个超级节点包含 256 个节点。Sunway 百亿亿级原型机的互连网络采用 28 Gbps 传输技术,节点带宽可达到 200 Gbps40。设计并发布了新一代的 Sunway 高阶路由器和 Sunway 网络接口芯片,采用双轨、fat tree 拓扑,定义并实现了新颖的 Sunway 消息原语和消息库,并实现了基于分组级别粒度动态切换的双轨道混沌系统。对于有序消息机制,其通信性能是 Sunway Taihu Light 互连网络的四倍38, 40-42。Sunway E 级超算计算机系统38, 40-42采用非阻塞的两级 fat-tree 网络,构建了具有点对点、高带宽通信性能的高性能互连网络。Dawning E 级超级计算机包含 512 个节点,每 16 个节点可形成一个超级节点。采用 200 Gbps 以太网,在 6D 环状结构的基础上构建网络38,单个节点的最大网络带宽可达 200 Gbps。整个网络拓扑分为三个层次。第一层是超级节点层,每个超级节点内部的节点实现全互联结构;第二层实现超级节点与多个超级节点之间的互联结构,节点构成一个硅元件;第三层是硅元件之间的互连,采用 3D 环状结构。同时,硅元件之间的快速光纤链接减少了通信跳数,从而提高了全局通信性能38。Dawning E 级超级计算互连架构预计将采用 500 Gbps 网络38,基于 6D 环状作为基本互连结构,以解决环面网络跳数过多的问题。利用光学快速通道技术构建光电混合网络架构38。
2.6 Bull BXI ICNBull BXI(Bull eXascale Interconnect)是 Bull 的第一代 E 级超算计算机互连网络架构15,支持单端口 100 Gbps。Tera1000-2 系统采用了Bull BXI 1.2 互连,截至 2021 年11 月在 Top500 中排名第 42 位。BXI 与 InfiniBand 的专有协议实现不同,它采用一种可靠的“保序”网络架构。BXI 最多可扩展至 64k 节点,支持多种网络拓扑,如f at-trees、torus 和 butterfly 等。此外,它还支持自适应路由和灵活的路由算法优化,并提供死锁回避和负载均衡机制。图 815展示了 BXI 架构配置为两层 fat-trees 的网络逻辑配置和物理布局的示意图。
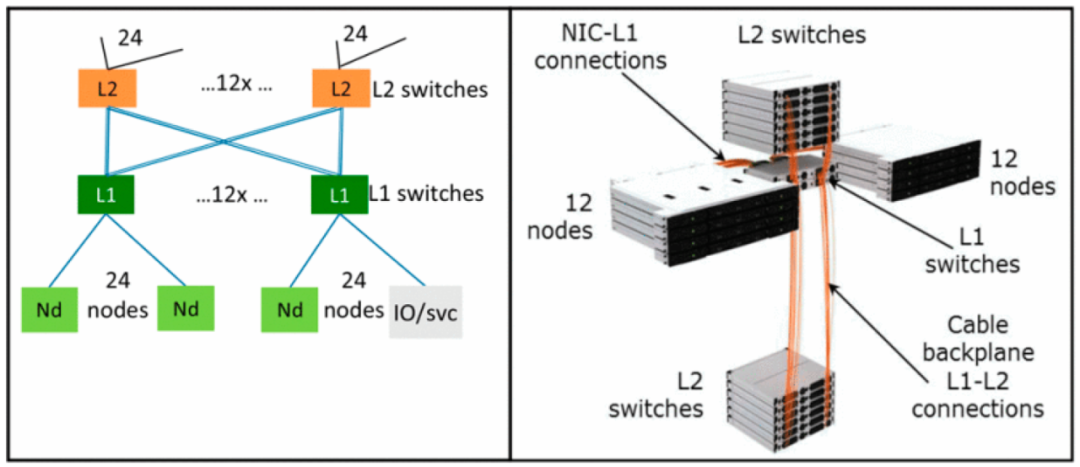
BXI 基于两块 ASIC 芯片:网络接口芯片 Lutetia 和网络交换芯片 Divio。Lutetia 实现了 Portals 443,44通信原语,其中一些功能可以绕过操作系统,例如识别逻辑-物理转换、虚拟-真实地址转换、对 Rendezvous 协议的硬件支持等,并支持集体通信的卸载功能。Divio 通过 19225 Gbps SerDes 实现了 48 个 HDR 端口,具有 200 Gbps 的双向网络带宽,吞吐率为 9.6 Tbps,延迟约为 130 纳秒。
3. 当前高性能互连网络面临的挑战
当前高性能计算机性能的提升主要依赖于增强单节点计算性能和增加计算节点数量。随着单节点计算能力的提升,节点通信带宽也需要相应增加,以最大程度地发挥节点的计算性能。以 Tianhe-2 为例,单节点的峰值性能为 3 TFLOPs,而节点通信带宽为 112 Gbps,通信计算性能比为 0.037。在 E 级超算计算机中,单节点的峰值性能可达到 10 TFLOPs45。为了保持通信计算比在 0.04 左右,网络带宽已经设计达到了 400 Gbps46。在 E 级超算计算机系统中,对网络带宽的需求更高,这在当前物理层面上对 SerDes 处理技术提出了很大的挑战。与此同时,随着网络直径的增加,节点通信延迟也会增加。这些都是未来超级计算机将面临的重要挑战46。
在 E 级超算计算机时代,互连网络面临的主要问题涵盖了解决功耗、密度、可靠性和成本等多个方面。本文接下来将从功耗、可靠性和密度等角度对互连网络的主要挑战进行分析。
3.1. Dennard 缩放效应减缓,互连功耗难以承受
尽管摩尔定律维持了几十年,但它在 2000 年左右开始减缓,到 2018 年,摩尔的预测和实际技术能力之间出现了大约 15 倍的差距,正如摩尔在 2003 年时所不可避免地观察到的。目前的预期是,随着 CMOS 技术接近其基本极限,这个差距将继续扩大。
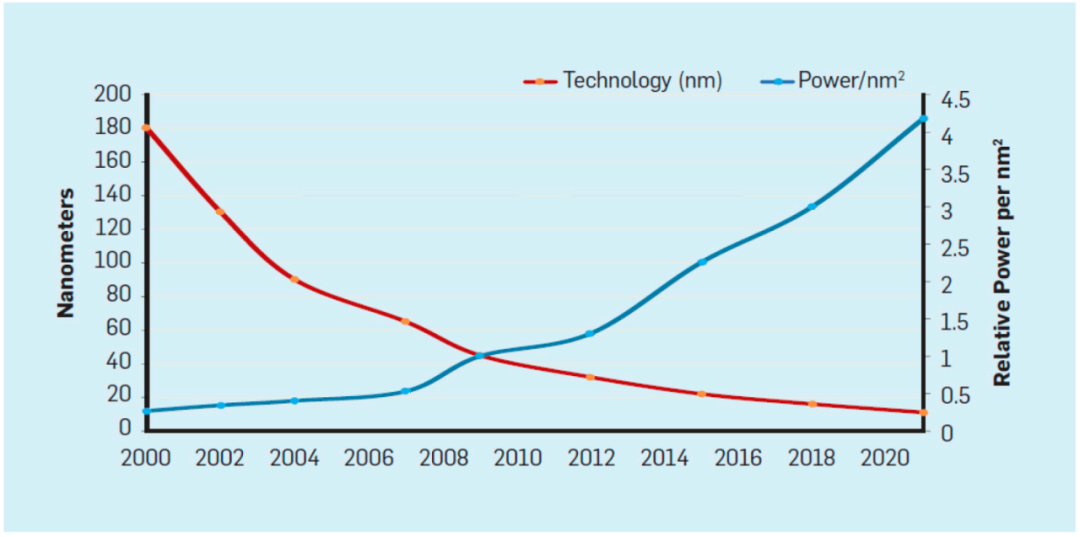
随着摩尔定律的出现,Robert Dennard 提出了一项被称为“登纳德缩减定律”的预测48。这一预测认为,随着晶体管密度的增加,每个晶体管的功耗将降低,因此每平方毫米硅的功耗将保持近乎恒定。随着每一代技术的推进,每平方毫米硅的计算能力都在增加,使得计算机变得更加节能。然而,登纳德缩减定律在 2007 年显著减缓,并在 2012 年几乎消失为零,如图 9 所示49。自 2007 年以来,这种缩放效应一直在减缓,直到 2012 年每平方纳米的功耗开始迅速上升,导致能耗增加,效率下降50-52。功耗问题已经成为芯片设计中的一项重要挑战。
随着互联传输技术的不断进步,系统互连网络广泛采用了多通道串行传输技术,以实现通道传输,从而提高端口带宽13。每个互连接口都集成了一个到多个高速 SerDes,而单个 SerDes 的传输性能已从最初的 1.25 Gbps 迅速提升到 50 Gbps。虽然 SerDes 的带宽持续增加,使得高性能芯片能够以更少的引脚实现更高的吞吐量,并多年来一直推动着互连网络的带宽不断提高52。然而,尽管 SerDes 的性能不断提升,但近年来每比特传输所需的 SerDes 功耗下降速度较慢。根据国际互连论坛(International Interconnection Forum)的统计数据,每一代 SerDes 速率增加一倍只会使每比特性能降低 20%53。以 Tianhe 超级计算机为例,Tianhe 1A 网络路由器芯片集成了 128 通道的 10 Gbps SerDes,总功耗约为 51.2 瓦,吞吐率达到 2.56 Tbps;而 Tianhe 2A 网络路由器芯片集成了192 通道的 14 Gbps SerDes,总功耗约为 90 瓦,芯片的总功耗约为 120 瓦,吞吐率为 5.376 Tbps14。假设单芯片功耗上限为 200 瓦,而内部切换逻辑所需的功耗基本保持在 40 瓦左右,则单芯片上可以集成的 50 Gbps SerDes 数量约为 160 个通道,单芯片吞吐率约为 16 Tbps。如果 SerDes 传输效率不能提高,那么 100 Gbps SerDes 的数量可能被限制在约 80 个通道,这将制约芯片吞吐率的进一步提高12。
如果不能妥善解决 SerDes 性能问题,系统网络的功耗将变得难以承受。随着节点性能的提升,单个节点所需的网络带宽也需要相应增加。SerDes 的性能问题不利于设计高基数网络,从而导致系统功耗恶化。当前的互连网络正在向高基数网络发展;即单个路由器芯片集成的网络端口数量不断增加。从最初的 8 个端口,逐渐增加到 16 个端口,24 个端口14,36 个端口18,48 个端口6,15,甚至达到 64 个端口19,显著减少了网络中的路由器数量,从而减少了网络的跳数,降低了传输延迟,提高了网络可靠性,并降低了系统功耗。根据先前的分析,假设每个端口的带宽为 800 Gbps,在一个 200 瓦的芯片预算下,只能设计 40 个网络端口。建立一个高基数的网络十分困难,互连网络将需要更多的路由器,这将加剧电力消耗问题。
3.2 SerDes 带宽持续增加,互连可靠性面临更大挑战
HDR 网络基本上可以满足当前 E 级超算计算机高性能的互联需求,但未来需要进一步将单通道速率提高到 100 Gbps NDR。光互连论坛(OIF)已完成了 112 Gbps SerDes 规范的制定54。高速互连已升级至 100 Gbps,并掀起了一波新的研发潮流。NVIDIA InfiniBand 已经推出了最新的主机通道适配器 ConnectX-7 和交换机 Quantum-2,支持 NDR InfiniBand 400 Gbps 互连技术18-20。Inphi、InfiniBand、Jinglue Semiconductor、Guangzi Technology 等公司已经推出或正在开发 112 Gbps SerDes,为新一代互连网络提供物理层基础。主要制造商如思科和华为将掀起一波 800 Gbps 端口系统的浪潮。随着单通道 SerDes 带宽的增加,高性能计算系统的互连网络可靠性设计面临更大的挑战52。
56 Gbps 高速传输的出现使高速 PCB 板设计变得越来越复杂55。目前,在芯片之间仍然广泛使用许多电气连接。例如,路由器通过背板连接。即使使用了光连接,切换芯片和光模块也需要通过电气连接进行连接。信号传输速率越高,对信号完整性的要求就越高。电阻-电容效应、信号串扰、反射等多种因素,以及皮层效应、天线效应等因素都必须考虑进去,而且芯片引脚的扇出方法需要受到严格限制55。高速信号线的线宽、线间距、布线层规划、穿孔设计、反钻等设计参数将显著增加 PCB 板设计的难度。同时,由于 PCB 布局和系统的物理结构,高速信号线仍需要在 PCB 上传输足够的距离,这将进一步增加 PCB 设计的难度52。通过采用质量更高的 PCB 板或增加 PCB 布线层数,可以缓解相应的困难,但这将显著增加 PCB 设计成本或降低 PCB 的可靠性。电信号传输的可靠性下降了,网络传输的延迟也增加了。在大规模网络应用中,采用更高速的电信号传输并不有利于减少互连网络的传输延迟。随着电信号的传输速率不断提高,SerDes 信号在 PCB 上的串扰效应、电磁噪声、信号反射等现象将降低信号线传输的可靠性52。
在 14 Gbps 链路速率以下,通常假设信号传输误码率可达到 10-12;而在 25 Gbps 以上的链路速率下,通常假设信号传输误码率可达到 10-9,可靠性降低了 3 个数量级55。为了在低可靠性链路上实现高可靠性数据传输,需要具有更强纠错能力的链路层编码技术,如前向纠错(FEC)。尽管这些编码技术可以提高可靠性,但它们将显著增加网络传输延迟。根据经验,在不使用 FEC 编码的情况下,单芯片延迟为 100 纳秒;而使用 FEC 编码后,延迟增加至 500 纳秒,网络传输延迟明显恶化。
如果我们继续采用现有方案,通过长传输路径传输的 100 Gbps 信号引起的串扰效应、反射效应和信号衰减将成为影响可靠性的关键因素。相比之下,光信号采用不同波段进行光波传输,不存在信号失真或时钟失真,数据串扰显著减少56-58。
3.3 随着处理器性能和 SerDes 端口速率之间差距的扩大,互连工程密度实现的难度正在增加
在高性能计算机(HPC)中,密度是影响系统可靠性、性能和可扩展性的重要因素48。
第一个因素是芯片有效高速信号的引脚密度。随着芯片设计技术的不断改进,晶体管的尺寸不断减小,更多的设计资源可以集成在一个芯片中。另一方面,芯片上的引脚数量增长非常缓慢。国际半导体技术路线图(ITRS)预测59,2007 年、2015 年和 2022 年芯片 I/O 的最大数量分别为 2200、2800 和 3420。在很长一段时间内,I/O 数量的缓慢增长将难以满足 I/O 需求。增加单个芯片引脚的带宽可以在一定程度上缓解引脚数量缓慢增长的困境。例如,处理器的内存访问接口已逐渐从 DDR2 升级到 DDR4,处理器的内存访问带宽在有限的引脚约束下仍然可以不断提高。然而,考虑到超过 10 Gbps 的高速引脚,增加引脚速率可能导致有效引脚密度的降低,从而影响引脚带宽的增加。这主要是因为更高速的引脚具有更高的功耗,可能需要更多的功率引脚;此外,由于信号完整性的限制,更高速的引脚需要增加更多的地面(GND)引脚,以实现高速信号之间的隔离。根据工程经验,近几代交换芯片的引脚数量仅从 2500 多增加到 2800 多,仅增加了 8.6%。尽管集成电路技术和封装的不断改进使 I/O 数量略有增加,但人们发现高速信号的密度已经减小,高速信号的数量减少了 25%。更高的单通道传输速率意味着更高的功耗,需要更多的电源引脚和 GND 引脚。随着互连传输速率的增加,芯片的高速引脚密度反而减小。这个问题将导致未来网络交换芯片端口数量下降,芯片交换吞吐量增长缓慢,网络互连的跳数增加,网络规模的可扩展性受到限制。
第二个因素是 PCB 板的密度。目前,限制 PCB 板密度增加的因素主要有两个。首先,随着芯片中 SerDes 带宽的增加,为了确保 SerDes 信号的完整性,在芯片封装设计和 PCB 设计中需要预留 SerDes 信号12。较大的线间距导致对芯片信号更大的扇出区域需求,增加了 PCB 设计密度的难度。其次,光电混合传输技术广泛应用于构建大型系统56,57。PCB 板需要集成光模块。由于光模块的特性要求,光模块通常安装在 PCB 板的边缘或面板上。受 PCB 板尺寸的限制,单块 PCB 板上可集成的光模块数量非常有限,通常不超过 24 块,这也限制了 PCB 密度的增加。即使使用更昂贵的板载光模块,密度也只能增加约三倍,仍然难以满足未来高性能计算机(HPC)的设计密度要求。
上述提到的芯片引脚密度问题和 PCB 板密度问题使得难以有效提高网络工程的密度。在高性能计算机领域,大量的交换机和光纤电缆已经成为影响网络工程的主要因素。根据摩尔定律,高性能处理器的性能每 18 个月翻一番,这一观点最早在 1975 年提出60,尽管在 2000 年左右开始放缓,到 2018 年,摩尔的预测与当时的实际能力之间存在大约 15 倍的差距;摩尔在 2003 年观察到这是不可避免的。当前的预期是随着 CMOS 技术接近基本极限,这一差距将继续增大47。与此同时,SerDes 端口速率每 3 到 4 年翻一番56;因此,处理器性能和端口速率之间的差距正在逐渐扩大。在高性能计算机中,为了保持全局均衡的性能通信比率,通常会通过增加交换机数量来换取总带宽的增加。例如,Tianhe 2A 超级计算机需要 125 个计算机柜和 13 个通信柜;Sunway 超级计算机需要 48 个机柜和 8 个通信柜。
随着计算性能的提高,通信柜与计算机柜的比例已成为网络工程的瓶颈21。如果继续使用现有结构,高性能系统通信柜的数量可能会超过计算机柜的数量,互连网络的工程密度将面临重大挑战。
4. 高性能互连网络的趋势
高性能互连网络是高性能计算机的重要设施。目前,主流的高性能互连发展迅速,主要呈现四个趋势。首先,高性能互连率先以 100 Gbps 的线速为目标,提高互连通信带宽。其次,为了减少传输延迟,互连和计算不断融合并深化合作。第三,采用多协议网络融合架构以降低成本。第四,基于芯片组的光电共模集成封装正在提高系统的密度。
未来,摩尔定律将面临来自物理极限和经济约束的多重压力47。高性能计算机的发展代表了电子信息技术发展的前沿。在高性能计算领域,建议通过硅光集成和基于碳纳米管替代硅基半导体57,实现计算和网络的集成,加强基础前沿技术的颠覆性突破53。高性能互连网络计划从“More Moore47”、“More than Moore47”和“Beyond CMOS55”的三个主要方向进行拓展,涉及颠覆性的新技术,如系统集成、系统封装、新材料、新器件等53。我们必须探索技术突破,解决未来超大规模网络中超高速、超低时延、高密度、低成本、高可靠性的技术瓶颈,实现新型智能集成高性能互联网络。
4.1 基于计算与互连集成以及多网络融合的系统集成
“More Moore47”涉及继续摩尔定律的本质,其目标是减小数字集成电路的尺寸,同时优化设备的性能和功耗。
随着芯片设计技术的不断进步,包括单处理器/加速器在内的计算节点性能得到了迅速提升,对互连网络的传输延迟也提出了更高的要求。在现有技术框架下,处理器和计算节点通过网络接口芯片连接到系统互连网络。计算节点和网络接口通过 PCIe 互连实现 I/O 结构的连接。在端到端的网络通信过程中,数据需要通过 PCIe 接口两次传输,而 PCIe 通信延迟占总延迟的比例很大(大约占总端到端延迟的 66%)。鉴于 PCIe 的 I/O 互连和松散耦合的存储架构,要进一步降低延迟并满足即时响应的要求变得相当困难。因此,如果能够实现计算节点和网络接口之间共享数据的一致性维护,就可以直接在处理器的一致性域中支持网络接口的访问,而无需使用 PCIe 的 I/O 空间映射,从而显著减小网络延迟,提高网络性能。随着 5G、云计算、人工智能等技术的崛起,以及网络传输速率的持续提高,处理器的数据发送和接收量以及计算和存储数据量都呈指数级增长。仅仅处理网络协议的数据已经超过了服务器 CPU 的计算能力。例如,实时处理 10 Gbps 的网络数据包可能需要大约 4 块 Xeon CPU 核。仅网络数据包处理就可以占用 8 核高端 CPU 的一半计算能力。如果考虑在 100 Gbps 高速网络中处理 40 Gbps 的情况,性能开销甚至更加难以承受。
通过在传统网络接口中集成一定数量的处理器计算核心,将计算能力延伸至网络边缘,并将原本由服务器 CPU 处理的一些任务转移到网络接口上,实现计算和通信的整合。这种技术通常被称为智能网络接口卡(SmartNIC)技术。SmartNIC 能够卸载服务器 CPU 处理现代分布式应用所需的各种任务,使服务器 CPU 能够专注于复杂计算和关键处理任务。在网络接口芯片中,可以完成存储、加解密、聚合通信、深度数据包检查和复杂路由等多种功能,这将大大减轻服务器 CPU 的计算负担,从而提高整个网络的性能。通过使用一致的芯片间互连接口替代 PCIe,以减少数据传输延迟。同时,在网络接口中集成了一定数量的简化处理器核心,实现了将计算节点任务卸载到网络接口上,并实现了网络与计算的深度集成。这不仅是实现低延迟、低功耗和高密度互连的重要手段,也是下一代互连网络的重要发展趋势之一。
此外,随着 HPC、大数据和 AI 计算的融合,多网络融合是未来互连网络发展的重要趋势,主要表现在两个方面:首先,以太网协议广泛应用于数据中心。通过支持 RoCE(在以太网上的 RDMA)、iWARP 等新技术,不断融入 HPC 高速网络,极大地降低了远程内存访问通信的传输延迟,为高性能计算和 AI 计算应用提供了更好的支持。其次,采用 InfiniBand EoIB 协议与以太网进行融合18-20。
NVIDIA 一直致力于整合 InfiniBand 高性能网络与以太网网络,推出了多款多网络集成芯片产品。其最新的网络不仅支持数据中心应用,还提供块级加密功能。数据在传输时必须通过硬件进行加密,并在存储或检索时进行解密。这一设计支持在共享相同资源的用户之间进行保护,降低延迟,减轻 CPU 负担。符合联邦信息处理标准,减少了对自加密磁盘的系统要求。通过通信加速器、可扩展的分层聚合和归约技术,满足从高性能计算到机器学习,甚至最苛刻的应用程序所需的网络带宽和延迟要求。InfiniBand 的 Harrier 网络基于 HPC 互连,集成了 PCle 网络、100 G 以太网以及监控与管理网络。PLX 最初专注于 PCle Switch,但现在逐渐发展为基于多个 PCle 的 PCle 网络66,67。Cray 的新一代 Slingshot 互连采用“HPC 以太网”架构,实现了高性能互连网络和以太网的融合。将传统的高性能互连技术扩展到支持数据中心网络协议堆栈已成为当前国际高速互连领域的重要发展趋势。
4.2 基于光电融合和芯片组的 D-System 集成封装
“More than Moore47”涉及改进芯片性能,不再单纯依赖于纯粹的晶体管堆叠,而是更多地依赖于电路设计和系统算法的优化;同时,借助先进的封装技术实现异构集成,即依靠先进技术集成实现的数字芯片模块来提高芯片性能。
随着系统规模的扩大和通信带宽的提高,光互连已经逐渐成为大规模互连网络构建中不可或缺的重要实现技术。光互连技术的趋势是进一步渗透到板级和芯片封装级设计。高密度光电一体化技术目前是提高芯片集成密度和系统互连密度的最重要推动技术之一,也是当前国际研究中备受关注的领域。基于芯片组的 2.5D 集成封装也是未来芯片封装的趋势。EPI 首款 CPU 原型 EPAC 1.0 测试芯片于 2021 年推出,采用 RISC-V 架构,基于 22 纳米工艺69。在 EPI(欧洲处理器倡议)项目计划中,每个处理器将包含四个 VPUs(矢量处理器),以及 EXTOLL 超高速网络芯片和 SerDes 互连技术。这些芯片预计将被封装成芯片组。采用 ARM 架构的 RHEA SoC 将包含 72 个 Arm Neoverse Zeus 内核,采用网格布局,2.5D 封装,集成 HBM 和网络互连模块,并将使用 TSMC 的 6 纳米工艺制造。涉及到的一些公司和项目,如 Ayar Labs、Rockley、RA-NOVUS、Sicoya、Leti 等,都是硅光子学领域的新兴力量,它们推动着硅基光电一体化在各种应用中的推广。
4.3 超越 CMOS:探索新器件和新材料
“Beyond CMOS53”涉及对新原理、新材料和新结构的器件和电路的探索,发展成纳米、亚纳米和多功能器件,并发明和简化新的信息处理技术,以超越 CMOS 器件的限制。
高性能计算机的发展标志着电子信息技术的前沿。我们建议在未来高性能计算中,加强光学计算机颠覆性基础技术的突破,并考虑用碳纳米管替代硅基半导体。
未来,基于光学计算和超导计算原理的新型设备将成为 Dawning 超级计算机处理器设备改革的重要方向53。相对于电信号,光信号具有强大的抗干扰性和并行性。在多个领域,基于光学原理构建的数字计算系统和模拟计算系统展现了巨大的计算潜力。构建的高速低功耗计算系统在计算能力和功耗方面具有显著优势:例如,单片光学矩阵计算芯片可以完成每秒 2 pb 的神经元运算,功耗仅为几十瓦特58。单芯片集成的光子器件呈指数增长,满足了未来在设备层面构建光学计算系统的需求。在传统电子计算机中,处理器核心的功耗是限制处理器主频提升的主要因素61。目前,高性能计算机中使用的处理器的工作频率普遍低于 5 GHz,这限制了整个计算系统的计算能力;而超导计算器设备利用材料接近绝对零度时的无电阻特性,消除了电流通过时产生的损耗和热量。功耗问题不再是处理器核心主频提升的限制因素。因此,基于超导设备构建的处理核心主频可以达到 50 GHz 甚至更高。作为一种先进技术,超导器件的应用同时解决了功耗和散热的两个问题,未来将使高性能计算机的能效比提高 100 倍53。
随着硅基 CMOS 工艺的不断改进,晶体管的通道将变得越来越短,短通道效应将变得愈加显著,导致晶体管的漏电电流不断增大。此外,制造工艺的差异对器件的影响也日益加大,摩尔定律所面临的物理瓶颈问题变得更加严重。在少数可能的替代材料中,碳基纳米材料(尤其是碳纳米管和石墨烯)被认为是最有前途、可以取代硅的材料,因为它们比硅基器件速度更快,能耗更低。并且在室温下具有更高速的电子和空穴的高固有迁移率,超过了最好的半导体材料55。因此,我们应该将碳纳米管作为半导体制造的新材料来探索,而不是使用硅基半导体。制造碳纳米管场效应晶体管(CNFET)已成为下一代高性能计算机的主要目标。作为应对后摩尔时代的举措,美国国防高级研究项目局(DARPA)70,71启动了电子复兴计划(ERI)72。在众多计划中,DSOC 项目是六个项目中资金最充裕的一个73。该计划的目标是寻找新的材料形式,如碳纳米管,并利用单片 3D 集成技术在 90 纳米工艺下实现 7 纳米芯片的能效提升,使性能与功耗的比值提高 50 倍以上。研究表明,CNFET 的能效约是硅的 10 倍,运行速度也比硅快。从功能上看,CNFET 可以替代传统的硅基晶体管,构建复杂的逻辑电路。CNFET 通过一排碳纳米管取代了传统 MOSFET 晶体管的硅基通道。与基于硅的 CMOS 技术相比,CNFET 具有更高的导电效率和更快的速度,将能效提高了 10 倍以上。碳纳米晶体管的制造可在 400℃ 以下完成,而不会损害其他层的电路,并且能够实现更好的通道控制68。因此,近年来碳基纳米材料的芯片研究备受关注,尤其是在美国,这将为摩尔定律走到尽头提供一种新的前进方式。
5. 总结
超级计算机已经进入了 E 级超算计算机时代,而 E 级超算计算系统继续遵循技术路线图,不断提高处理器性能并增加处理器数量。单个处理器的计算能力超过了 10 TFLOPs,提供均衡通信能力的难度和成本远远超过了计算能力的提升。处理器数量超过了 10 万,通信线路数量超过了百万,集成电路逐渐迈入后摩尔时代,这为高性能互连网络带来了巨大挑战,包括功耗、密度、可伸缩性、可靠性以及互连网络系统成本等方面的挑战。高性能互连网络技术的趋势包括:首先,基于 100 Gbps 线速的高速互连提高互连通信带宽;其次,互连与计算的集成降低了传输延迟;第三,多协议网络融合架构降低了成本;第四,基于芯片组的光电集成封装提高了系统密度。在 E 级超算计算机代,高性能计算机互连网络的设计需要采用新的封装工艺技术、新的设计技术、新材料、新设备以及以及其他颠覆性的新技术,以实现技术突破。


