随着主要的半导体和数据中心公司陆续加入 CXL(Compute Express Link),并且第一代设备即将面市,CXL 的推广已经进入关键阶段。最近公布的第三代 CXL 规范带来了一系列显著变化,这些变化在之前的版本中并不存在。本文将讨论可组合服务器架构、异构计算以及 CXL 1、2 和 3 版。
在报告的后半部分,我们对即将推出的 CXL 产品进行讨论。这些产品来自 20 家不同的半导体公司,我们将探讨这些产品在市场上的机遇、时机以及功能特点。我们所认识的一位顶尖半导体投资者曾指出,准确理解和界定 CXL 对数据中心的影响将成为半导体行业获得 Alpha 的最重要来源,对此我们深表认同。这 20 家公司即将推出的产品包括 CPU、GPU、加速器、交换机、网卡、DPU、IPU、协同封装光学器件、内存扩展器、内存池器和内存共享器等。
我们将讨论的公司包括:英特尔、AMD、Nvidia、Ayar Labs、惠普企业、微软、Meta、谷歌、阿里巴巴、Ampere Computing、三星、SK 海力士、美光、Rambus、Marvell,、Astera Labs、微芯科技、Montage Technology、博通和 Xconn。尽管 CXL 联盟拥有 200 多家成员,但我们认为以上这些公司拥有最具影响力的产品和知识产权。
在过去,数据中心芯片的主要焦点是制造更好的 CPU 内核和更快的内存。十年前的服务器与今天的服务器在外观上几乎没有太大变化。然而,在过去的十年里,随着横向扩展和云计算的兴起,竞争格局发生了改变。最快的内核不再是唯一优先考虑的因素。如何以经济高效的方式提供整体计算性能,并将其连接在一起,成为了关注的重点。在我们的高级封装系列中,我们深入探讨了摩尔定律放缓以及半导体成本缩减对此的影响。
所有这些趋势表明,计算资源正逐渐向专业化方向发展。受递减规律的影响,通用 CPU 性能的提升遇到了瓶颈。每增加一个晶体管来提高通用 CPU 性能,其性能提升便会逐渐减弱。在这种情况下,异构计算正逐渐成为主流,因为专用集成电路(ASIC)可以利用更少的晶体管为特定任务提供比通用 CPU 高出 10 倍以上的性能。
设计特定芯片以满足各种工作负载的需求需要精确的计算资源分配,但其高昂的成本常使人望而却步。在我们题为《半导体设计复兴的黑暗面》的文章中,我们深入探讨了这一观点。简而言之,由于光刻掩膜的设置成本、验证和确认过程的费用,设计芯片的固定成本正在急剧上升。
与其为整个工作负载设计单一芯片,不如分别为各种计算任务设计专用芯片,然后通过适当的配置将它们连接在一起,以满足特定工作负载的需求。事实证明,采用较小的功能模块来构建大型系统更为经济高效,因为这些模块可以分别封装并相互连接。通过利用这些小型功能模块,结合功能设计和构建的支持,大型系统的服务提供商能够迅速且经济地设计和制造各种类型的设备。
1965 年,Gordon Moore 博士在预测“摩尔定律”的原始论文中提出了“将更多元器件集成到集成电路中”的概念。
系统构建方式的变化将计算单位从单一芯片或服务器提升到整个数据中心层面。
数据中心已成为新的计算单位。
Jensen Huang
在服务器内部,通常使用 PCI Express 进行芯片之间的连接。然而,这种标准存在一个重要的缺陷,即缺乏高速缓存一致性和内存一致性。为了更好地理解这两个概念,可以将服务器想象成一个邮局,就像信件是异步寄送的一样,新的信息通常会使得原始信息包含的信件在数天之后变得过时。一致性的概念有助于管理和平衡这种情况。
在使用 PCI Express 进行通信时,不同设备之间的通信开销在性能和软件方面通常较高。此外,连接多个服务器通常需要采用诸如以太网或 InfiniBand 等通信技术。然而,这些通信方式都面临着相同的问题,即延迟较高且带宽较低。
在 2018 年,IBM 和 Nvidia 在当时世界上速度最快的超级计算机 Summit 中采用了 NVLink,以解决 PCI Express 的局限性。而 AMD 在 Frontier 超级计算机中也采用了类似的专有解决方案,名为 Infinity Fabric。然而,尽管存在这些专有协议,但没有任何行业生态系统能够围绕它们发展。在 2010 年代中期,CCIX 曾被提出作为一个潜在的行业标准,尽管得到了 AMD、Xilinx、华为、Arm 和 Ampere Computing 等公司的支持,但由于缺乏关键行业支持,它从未真正推广开来。
由于 Intel 占据了超过 90% 的 CPU 市场份额,因此没有他们的支持,任何解决方案都不会成功。Intel 制定了自己的标准,并于 2019 年将他们的专有规范捐赠给了新成立的 CXL 联盟,即 CXL 1.0。这一标准得到了半导体行业大多数主要采购商的支持。CXL 利用了现有的 PCIe 5.0 生态系统,采用其物理和电气层,但在协议层面进行了改进,为负载存储内存事务增加了一致性和低延迟模式。
CXL 通过建立一个行业标准协议,得到了行业大多数主要厂商的支持,从而使得向异构计算的过渡成为可能。现在,业界拥有了将这些不同芯片连接在一起的标准互连技术。
在 2022 年底或 2023 年初,AMD 的 Genoa 和 Intel 的 Sapphire Rapids 开始支持 CXL 1.1 标准。CXL 1.1 引入了三个数据通道:http://CXL.io、CXL.cache 和 CXL.mem。http://CXL.io 类似于标准 PCIe,但经过了改进。CXL.cache 允许 CXL 设备与主机 CPU 的内存进行连贯访问和缓存,而 CXL.mem 则允许主机 CPU 连贯地访问设备内存。大多数 CXL 设备将同时使用 http://CXL.io、CXL.cache 和 CXL.mem 通道。
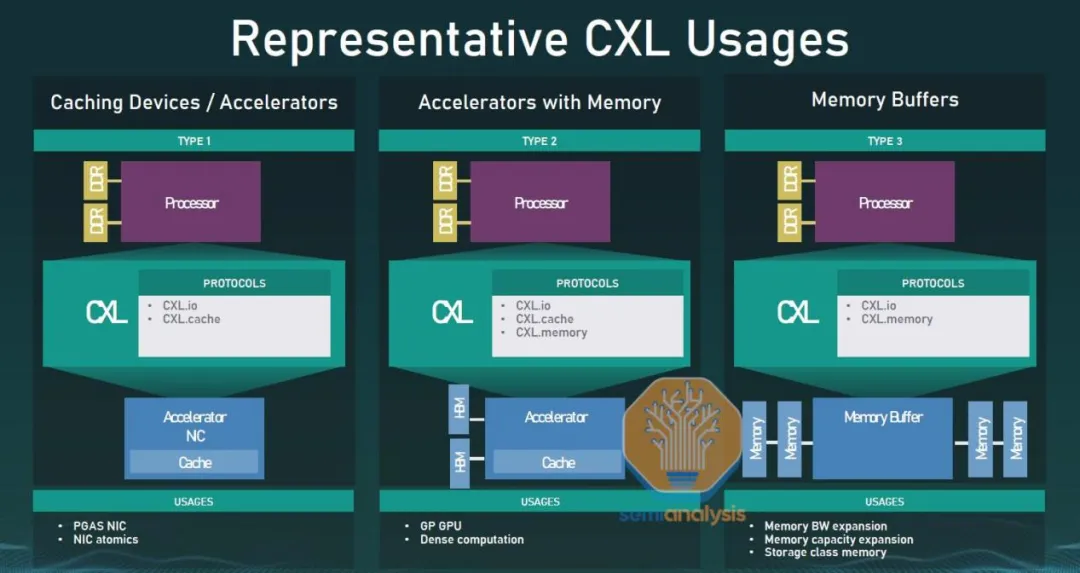
- http://CXL.io 是一种协议,可用于处理初始化、连接、设备发现、枚举以及寄存器访问等任务。它为 I/O 设备提供接口,类似于 PCIe Gen5。所有 CXL 设备必须支持 http://CXL.io 协议。
- CXL.cache 是一种用于定义主机(通常是 CPU)与设备(例如 CXL 内存模块或加速器)之间交互的协议。这使得连接的 CXL 设备能够通过安全地使用其本地副本,以低延迟地缓存主机内存。可以将其视为 GPU 直接缓存 CPU 内存中的数据。
- CXL.memory(CXL.mem)是一种协议,允许主机处理器(通常是 CPU)通过加载 / 存储命令直接访问连接到设备的内存。可以将其视为 CPU 使用专用的存储级内存设备,或者利用 GPU / 加速器设备上的内存。
到目前为止,我们主要关注了异构计算,但 CXL 的真正焦点是内存。我们在之前的文章中已经讨论过 Marvell 收购 Tanzanite Silicon 以及 Astera Labs 和 Rambus 在内存加速器领域的竞争。在深入研究微软的内存池解决方案时,我们进一步阐述了这一观点。现在,我们将在这里直接提供更详细的概述。
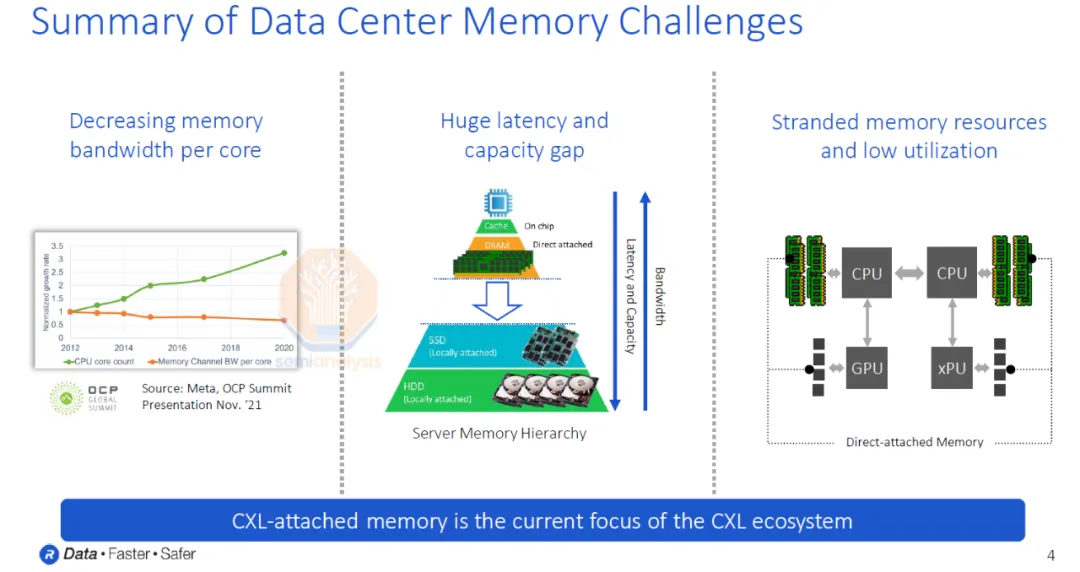
数据中心面临着诸多内存方面的挑战。自 2012 年以来,内核数量迅速增加,但每个内核的内存带宽和容量并未相应增长。实际上,自 2012 年以来,每个内核的内存带宽呈现下降趋势,并预计这一趋势将持续下去。此外,直接连接的 DRAM 和 SSD 在延迟和成本方面存在着巨大差距。最后,昂贵的内存资源通常利用率低下,这是一个致命的问题。对于任何资本密集型行业而言,低利用率都是一个重大负担,而数据中心业务则是全球资本密集程度最高的行业之一。
微软表示,服务器总成本的 50% 来自 DRAM。尽管 DRAM 成本巨大,但仍有高达 25% 的 DRAM 内存处于闲置状态!简而言之,微软 Azure 服务器总成本的 12.5% 是在做无用功。
想象一下,如果这些内存能够存在于一个相互连接的网络中,并且可以动态地分配给虚拟机,而不是被固定在单个 CPU 上。内存带宽便可以根据工作负载的需求进行调整,从而大幅提高内存的利用率。

这一理念不仅仅适用于内存,还涵盖了各种形式的计算和网络。可组合服务器架构是指将服务器拆分为各种组件,并将其组合在一起,以便在各个组件之间动态地分配资源给工作负载。
现在,数据中心机架被看作是计算单元。客户可以根据其特定任务的需求选择任意数量的核心、内存和人工智能处理性能。或者更为优越的做法是,像谷歌、微软、亚马逊等云服务商可以根据客户正在执行的工作负载类型动态分配资源,并根据客户的实际使用情况进行收费。
这一愿景被视为服务器设计和云计算领域的圣杯。然而,实现这一愿景,需要解决许多复杂的工程问题,其中许多问题都与延迟和构建网络连接所有设备的成本有关。这些问题必须经过严格审查,但协议的制定必须是首要考虑的,而这正是 CXL 2.0 和 3.0 所带来的。

CXL 2.0 的主要功能是支持内存池和交换。CXL 交换机可以连接多个主机和设备,使得连接在 CXL 网络上的设备数量能够显著增加。新的多逻辑设备功能允许多个主机和设备之间相互连接和通信,而无需建立传统的主从关系。网络资源将由“Fabric Manager” 来统筹,这是一个控制和管理系统的标准 API。通过细粒度的资源分配、热插拔和动态容量扩展,可以在不同主机之间动态分配和转移硬件,而无需重新启动。
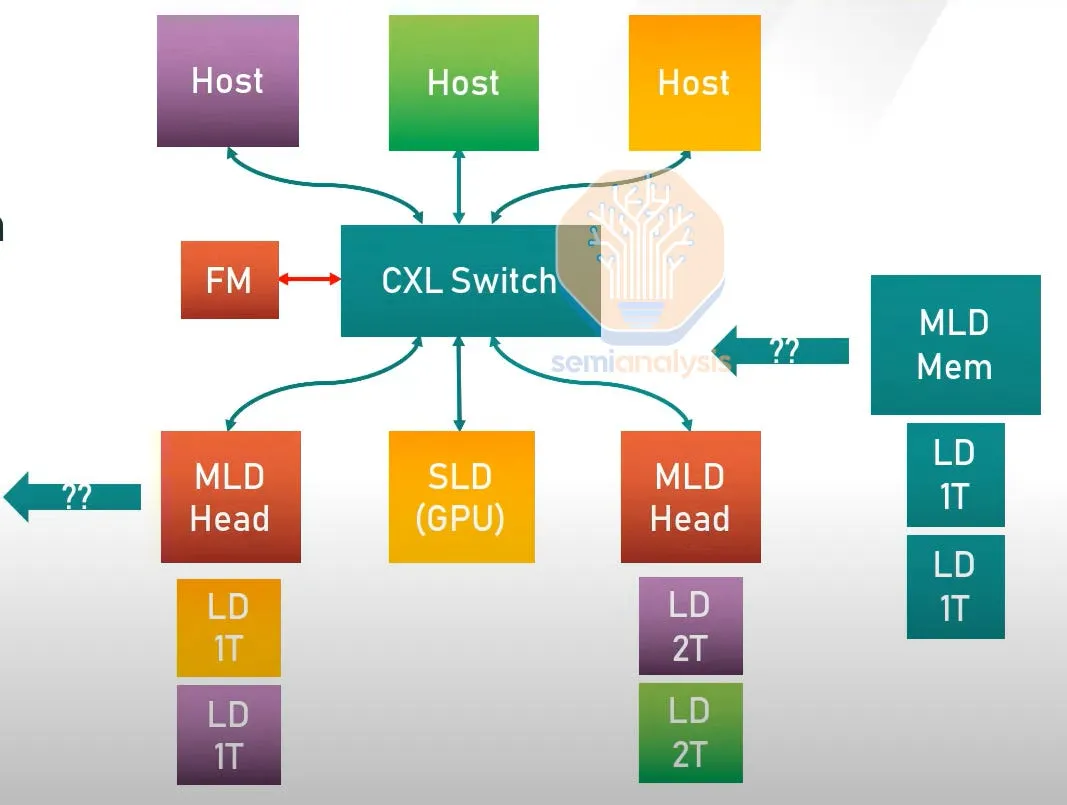
一图胜千言,接下来我们将讨论上图所示内容。多个主机可以连接到交换机。然后,交换机连接到各种设备,包括 SLD(单逻辑设备)或 MLD(多逻辑设备)。MLD 的设计旨在与多台主机相连接,以实现内存池的功能。
MLD 被显示为由多个 SLD 组成。这使它们可以在主机之间共享内存,甚至共享加速器计算资源。FM(Fabric Manager)位于控制平面,是协调者,负责分配内存和设备。Fabric Manager 可以独立部署在一个芯片上,也可以集成在交换机中;它并不需要很高的性能,因为它不直接处理数据平面。如果该 CXL 设备是多头的,并连接到多个主机的根端口,则可以在没有交换机的情况下实现这一点。
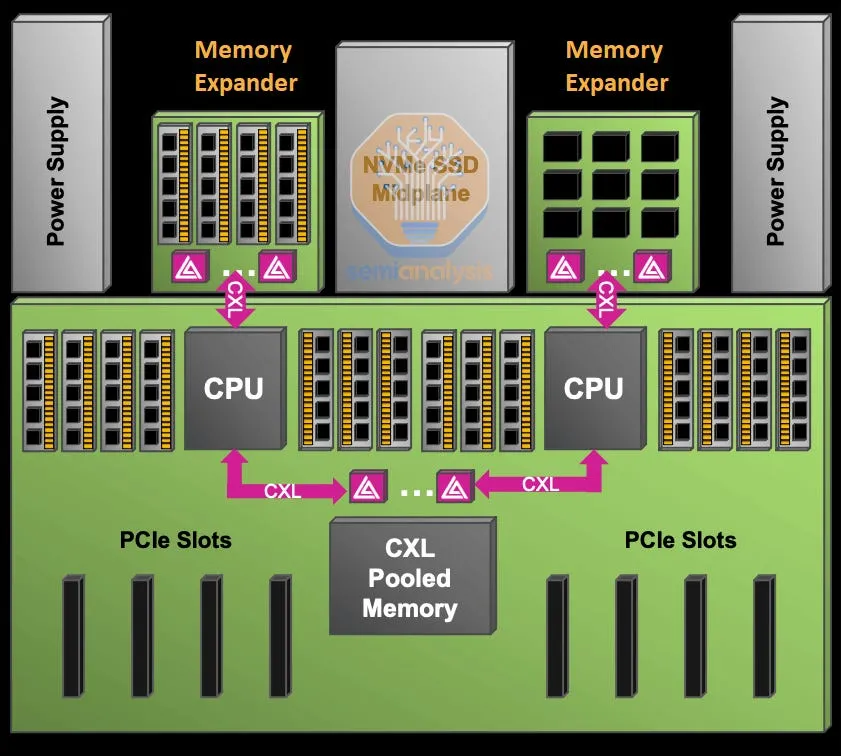
微软展示了通过汇集 DRAM 资源实现的成果,成功将部署的 DRAM 减少了 10%,从而节省了服务器总成本的 5%。这一成果是在未使用 CXL 交换机的第一代 CXL 解决方案上实现的。
CXL 3.0 带来了更多的改进,有助于扩展创建异构可组合服务器架构的能力。其主要焦点是将 CXL 的应用范围从单个服务器扩展到整个机架。这是通过将 CPU 视为网络上的另一个设备,而不仅仅是主机设备模型的一部分来实现的。
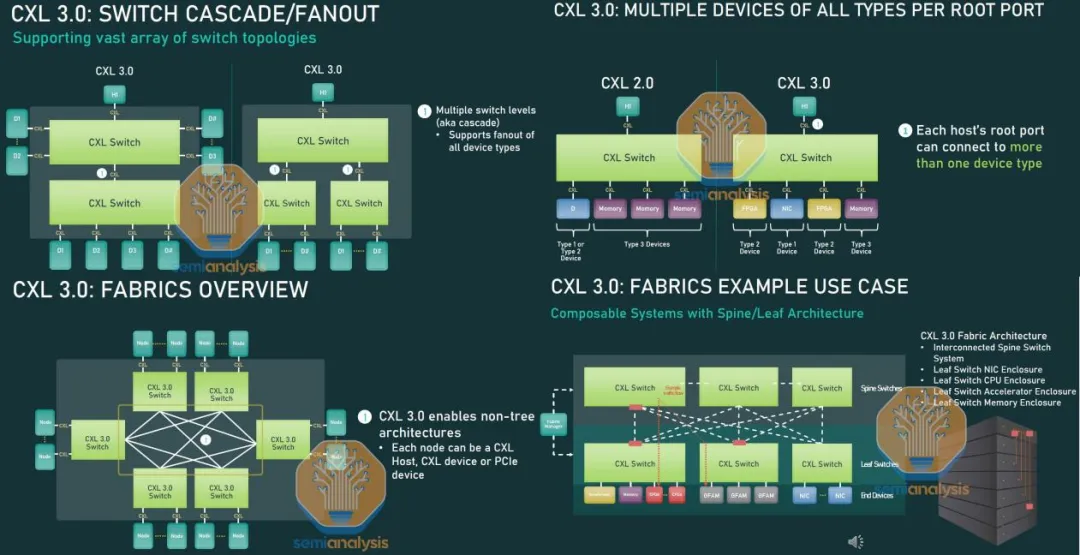
CXL 交换机现在支持一系列不同的拓扑结构。相较于 CXL 2.0,以前只能使用 CXL.mem 设备进行扇出。而现在,一个或多个机架的服务器可以通过叶型、脊型或全对全的拓扑结构相互连接。在 CXL 3.0 中,设备、主机和交换机端口的理论上限达到了 4,096 个。这些变化极大地扩展了 CXL 网络的潜在规模,从以往仅适用于几台服务器扩展到适用于多个服务器机架。
此外,现在所有类型的多个设备都可以通过一台主机接入 CXL 的单个根端口。这是一个之前存在的重大限制,因为单个根端口只能连接一种类型的设备。以前,如果一台主机连接到带有 CXL 单根端口的交换机,那么该主机只能访问交换机上的一种设备。
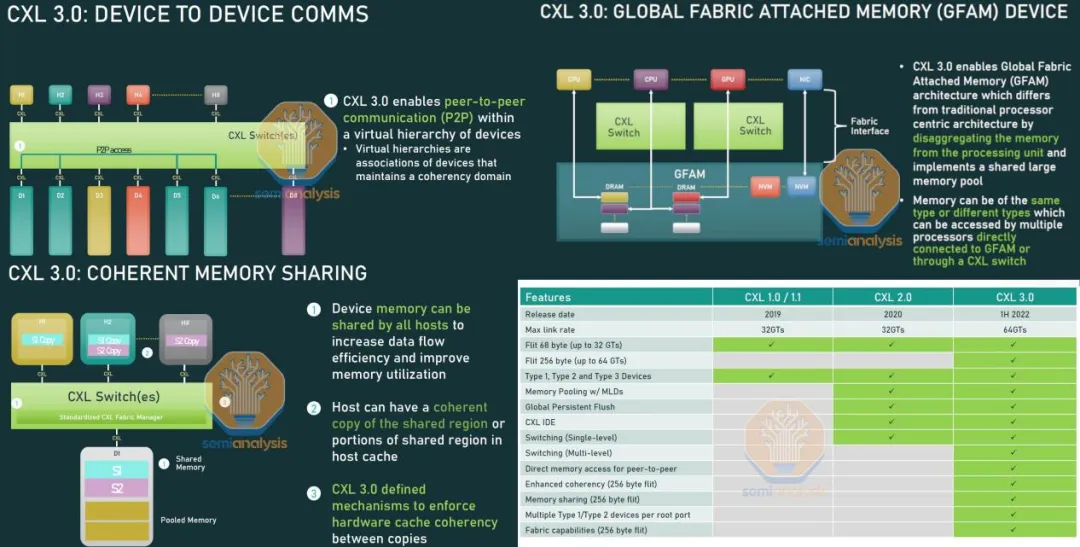
CXL 3.0 带来的最重要变化之一是实现了内存共享和设备之间的直接通信。现在,主机 CPU 和设备可以在同一数据集上协同工作,而无需进行不必要的数据移动和重复操作。一个典型的例子是常见的人工智能工作负载,例如谷歌和 Meta 等巨头采用的数十亿参数的深度学习推荐系统。在这些情况下,相同的模型数据会在多个服务器上重复存储,并在用户请求后进行推理运算。有了 CXL 3.0 的内存共享功能,一个大型人工智能模型可以存储在几个中央内存设备中,并且可以由多个其他设备共享访问。这个模型可以利用实时用户数据进行持续训练,可以通过 CXL 交换网络进行更新推送。这一变化可以将 DRAM 成本降低一个数量级,并提高系统性能。
内存共享在提高性能和经济性方面具有广泛的应用前景。第一代推出的内存池技术可将总 DRAM 需求降低 10%,而具有更低延迟的内存池则可将多租户云的节省率提高至 23%。此外,内存共享还能够将 DRAM 需求降低 35% 以上。这些节省的成本相当于每年数十亿美元的数据中心 DRAM 支出。
CXL 的用途
在本报告的后半部分,我们将探讨 20 家公司在 CXL 领域的产品、时机和战略。这些产品涵盖了交换机、网卡、数据处理单元(DPU)、智能处理单元(IPU)、协同封装光学器件、内存扩展器、内存池器、内存共享器、中央处理器(CPU)、图形处理器(GPU)和加速器等多个领域。
我们将会在仅限订阅者的部分讨论一些公司,包括英特尔、AMD、Nvidia、Ayar Labs、HPE、微软、Meta、谷歌、阿里巴巴、Ampere Computing、三星、SK Hynix、美光、Rambus、Marvell、Astera Labs、Microchip、Montage Technology、Broadcom 和 Xconn。我们将重点讨论非封装功能,而有关封装功能的内容将在稍后的有关 UCIe 的文章中单独讨论。
*以上文章翻译自《CXL Deep Dive – Future of Composable Server Architecture and Heterogeneous Compute, Products From 20 Firms, Overview of 3.0 Standard》,如需原文,请与我们联系。
WF Research 是以第一性原理为基础的专业顾问服务机构,欢迎关注和留言!
微信:Alexqjl


