什么是 RDMA
RDMA 技术允许两台服务器在不经过处理器、缓存或操作系统的干预下,直接读取或写入对方的内存。这项技术能够释放 CPU 资源,降低延迟,加快数据传输速度,从而让网络、存储和计算应用受益匪浅。RDMA 主要通过服务器的网络接口卡(NIC)实现,它绕过操作系统和网络内核,显著提升了两台服务器间的网络性能和数据交换速度。RDMA 最初是为高性能计算集群设计的,特别适用于需要大规模并行处理的计算任务。这种大规模并行计算正是 AI/ML 技术的基础,RDMA 在这些领域的应用部署中扮演着至关重要的角色。值得注意的是,RDMA 技术最初是在 InfiniBand 网络上开发的。
什么是基于融合以太网的 RDMA (RoCE)
基于融合以太网技术的 RDMA(Remote Direct Memory Access over Converged Ethernet,简称RoCE)是一种网络协议,它允许在以太网网络上实现高效的直接内存访问交换。RoCE 的早期版本依赖于融合以太网架构,但随着技术的发展,最新的 RoCE 版本已能够在标准的以太网网络上运行。RoCE 协议在以太网之上运行,需要以太网网络接口卡(NIC)的支持来完成数据传输。在行业层面,业界正在对以太网技术进行大量投资,以改善拥塞控制机制并减少数据流量的损失。值得注意的是,数据中心安装的以太网交换机端口数量已超过 4 亿个。鉴于以太网的普及性,它将在 AI/ML 网络中发挥越来越重要的作用。随着技术的不断进步,预计未来将有更多的 RDMA 操作通过以太网来执行。
介绍
在 2022 年之前,RDMA 技术主要应用于高性能计算(HPC)领域,特别是在超算项目中得到广泛应用,而在云和企业数据中心中的应用相对较少。然而,随着 AI 和 ML 在 2022 年底成为投资的焦点,数据中心的支出迅速从传统计算转向了 AI/ML 领域。这种转变带来的增长是空前的,到 2023 年底,RDMA 基础网络的增长速度甚至超过了 2022 年和 2021 年的总和。这一迅猛的增长使 RDMA 成为了主流,并对 AI/ML 的扩展至关重要。
服务器市场的变化
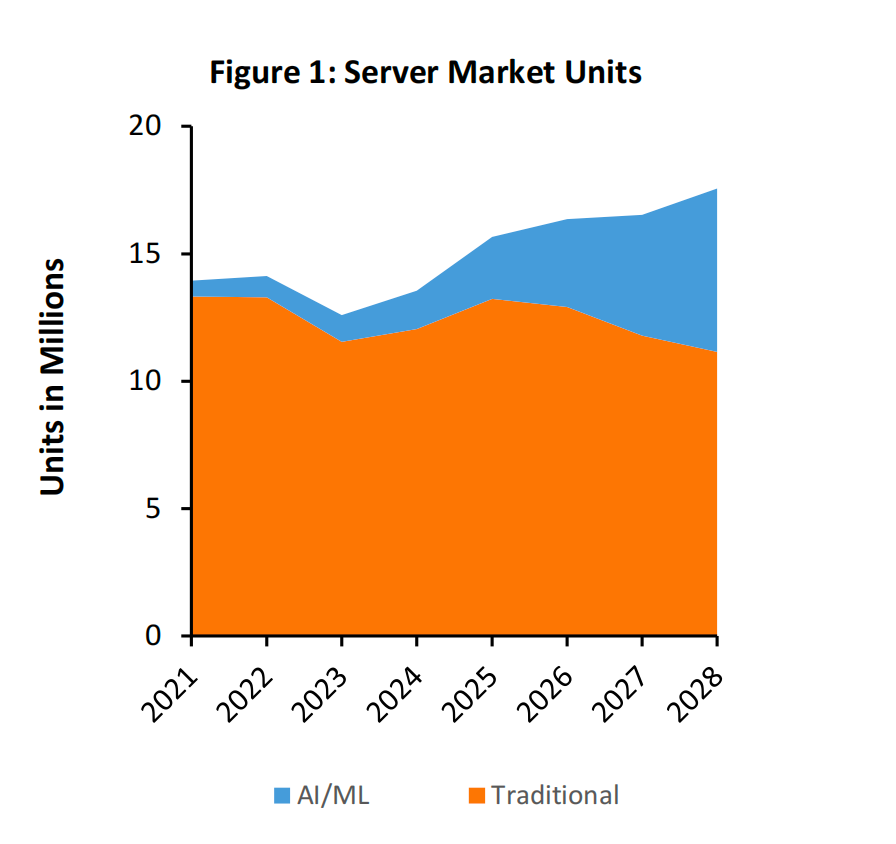
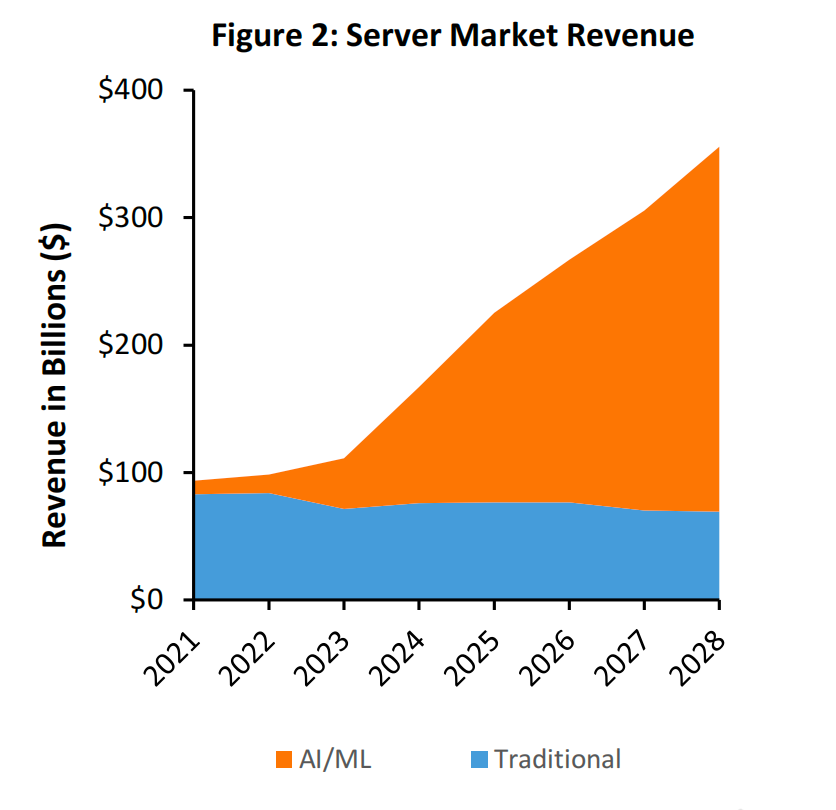
随着客户逐渐从通用服务器转向 AI/ML 服务器,服务器市场正在经历显著的变革。预计在这一转型过程中,AI/ML 服务器的数量将从 2023 年的 100 万台增长到 2028 年的 600 万台(参见图 1)。与此同时,AI/ML 服务器的支出预计将在 2028 年接近 3,000 亿美元(参见图 2)。数据中心市场从未经历过如此迅速且显著的增长,而 AI/ML 无疑将成为推动数据中心支出翻倍的主要驱动力。预计到 2028 年,这 600 万台 AI/ML 服务器将配备后端网络或 AI Fabric,实现计算资源的高效互联互通。
随着技术的不断进步,服务器中搭载的 GPU 和 AI ASIC 数量预计将持续增长。目前,配备 8 个 GPU 的服务器配置最为普遍,但预计到十年后,市场将扩展至 16 个甚至 32 个 GPU 的配置。随着训练模型的参数量从数十亿扩展至数万亿,每个 GPU 所需的内存容量也将相应增加。在这样的规模下,服务器间进行高效数据传输的能力变得尤为关键,它是实现和扩展这些庞大训练模型的基础。RDMA 凭借其高效的远程直接内存访问能力,在这些高性能服务器中扮演着至关重要的角色。特别是在需要跨服务器进行内存和资源访问的场景中,RDMA 的作用尤为突出。
作业完成时间(JCT)和性能指标
直接访问其他服务器的内存有助于提升AI模型的整体性能。RDMA 通过快速将数据传输到 GPU,有效地缩短了作业完成时间(Job Completion Time, JCT)。在早期的 AI/ML 集群中,GPU 核心的闲置是一个主要问题,这可能导致整个 AI/ML 集群因为数据包丢失或数据传输延迟而效率低下。RDMA 通过解决这些网络瓶颈,显著提高了 JCT 和 AI/ML 集群的整体性能。虽然以太网和 InfiniBand 在性能上可能存在差异,但 RDMA 相较于传统的网络解决方案,无疑是一个显著的进步。
网络接口卡(NIC)市场
所有 InfiniBand NIC 都支持 RDMA,但并非所有现有的以太网 NIC 都具备 RDMA 或 RoCE 功能。对于那些希望拓展到 AI/ML 市场的传统以太网 NIC 供应商来说,集成 RoCE 功能至其产品中是关键,这样才能与已经提供 RoCE 支持的竞争对手相抗衡。随着 NIC 的传输速度提升至 400 Gbps 甚至更高,预计大多数以太网 NIC 产品将开始支持 RoCE。随着功能的增强和端口速度的提高,预计以太网 NIC 的平均售价也将随之上升。
Ethernet NIC 中 RoCE 的性能表现因供应商所采用的处理器类型、附加的卸载引擎以及工程技术的不同而有所差异,从而形成不同的性能层级。随着新一代产品的推出,供应商们正致力于不断优化其产品性能,以实现 RoCE 性能指标在不同供应商之间的更高一致性。这种性能上的一致性不仅促进了产品间的互操作性,而且为终端用户提供了更广泛的选择空间。
AI/ML 后端网络
大多数 AI/ML 服务器都配备了独立的后端网络,这种网络配置独立于数据中心的其他组成部分,可以基于 InfiniBand 或以太网技术构建。后端网络的设计专注于强化 AI/ML 集群内部的连接,尤其是 GPU 之间的互联以及 GPU 与内存的直接连接。值得注意的是,后端网络是现有网络的扩展,它通过为每台服务器增加更多的端口,显著提升了网络收入的机会。
AI/ML 系统可以配置多个后端网络,以专注于不同的任务。例如,尽管 RDMA 能够在以太网和 InfiniBand 上运行,但不同的 GPU 供应商或 AI ASIC 制造商可能会采用额外的网络连接,以实现更高的性能解决方案。
市场规模
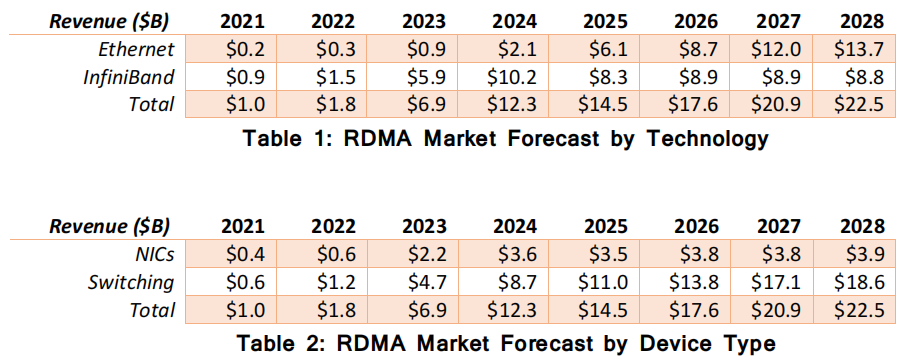
在 2021 年之前,具备 RDMA 能力的市场规模每年大约在 4 亿到 7 亿美元之间,主要由高性能计算(HPC)应用所推动。然而,到了 2023 年,随着 AI/ML 部署的迅猛增长,对 RDMA 的需求已经突破 60 亿美元大关。据预测,这一数字到 2028 年将超过 220 亿美元(见表 1、表 2 和图 3、图 4)。随着运营商增加对 AI/ML 的资本支出(CAPEX)并进行未来规划,预计未来几年 RDMA 相关的项目和市场预期将会进一步上调。
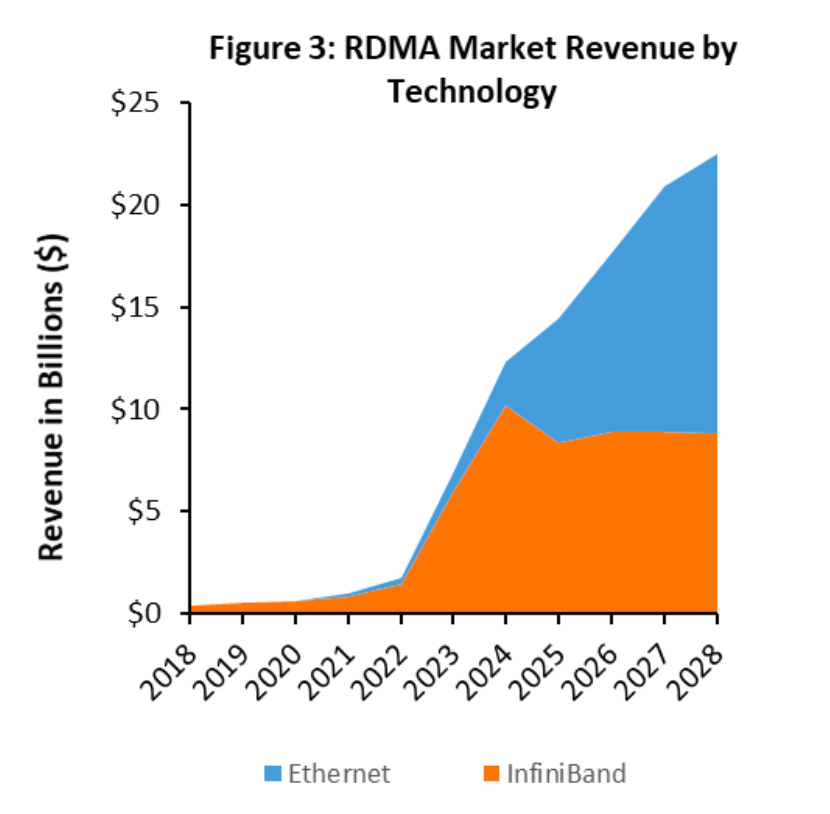
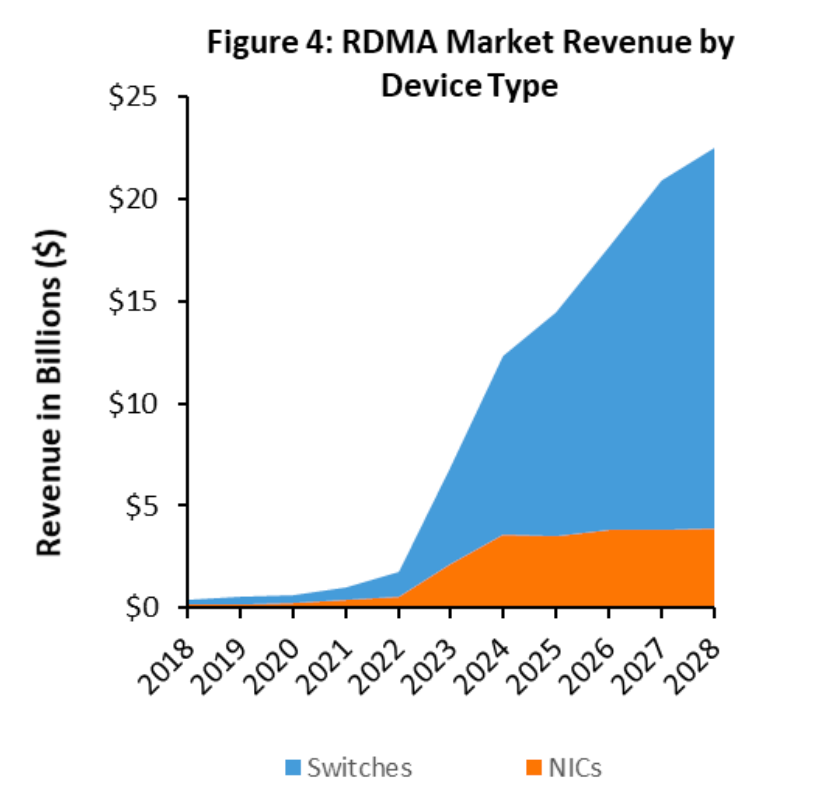
RDMA 市场主要分为两个不同的细分领域。首先是技术层面,目前 RDMA 技术主要部署在InfiniBand 上,但预计未来在以太网领域将出现更多 RDMA 网络的应用。第二个细分领域是网络接口卡(NIC)和交换机市场。在 InfiniBand 网络中,NIC 和交换机的采购通常同步进行。然而,在以太网网络中,交换机的采购往往由不同的团队负责,其采购节奏与 NIC 的采购也不尽相同。由于组织结构的限制,即使在 AI/ML 领域,服务器团队与网络团队的分离现象仍将继续存在。因此,在未来构建 AI/ML 网络时,每个客户都将对 NIC 和交换机供应商有自己独特的偏好,这些偏好可能与传统计算部署中的选择有所区别。
结论
RDMA 和 RoCE 在 AI/ML 网络中至关重要,缺少这两项技术,AI/ML 的发展速度将无法满足市场的需求。随着服务器市场迅速从传统计算转向 AI/ML,预计 RDMA 和 RoCE 的市场潜力将在未来几年显著增长。尽管客户和供应商对技术的偏好各有不同,但 RDMA 技术仍将持续繁荣发展。以太网和 InfiniBand 这两种技术将在市场上并存,客户不应将其视为二元选择。大多数客户将在 InfiniBand 和以太网上使用 RDMA,并混合使用不同的 GPU。只有极少数客户会完全依赖一种网络或供应商。AI/ML 的工作负载非常多样,包括基础训练、强化学习和推理等。RDMA 在多种技术上的应用有助于客户扩展并专注于 AI/ML 工作负载,而非底层网络。
以上内容翻译自《RDMA Networking and AI Research Report》,如需原文,请与我们联系。
WF Research 是以第一性原理为基础的专业顾问服务机构,欢迎关注和留言!
微信号:Alexqjl


