PART 01:引言

当前业界充斥着各种流行术语和最佳实践,但大多数都并未取得预期效果。我们需要一些更为根本且“不会出错”的东西。
在阅读代码时,我们有时会感到困惑,而困惑会消耗时间和资金。造成困惑的根本原因是高认知负荷。这并不是一个华而不实的抽象概念,而是人类认知能力的基本限制。它并非凭空想象,而是真实存在、切实可感的。
PART 02:认知负荷
- 认知负荷指的是开发者为完成一项任务所需进行的思考量。
在阅读代码时,诸如变量的值、控制流逻辑和函数调用顺序等信息都会被放进你的大脑。一般人工作记忆一次最多只能容纳大约四个这样的信息块。一旦认知负荷达到这一上限,理解难度就会显著上升。
设想我们要对一个完全陌生的项目进行修复,而据说该项目之前有位非常聪明的开发者参与,使用了许多炫酷的架构、花哨的库以及流行技术。换句话说,此人给我们留下了极高的认知负荷。
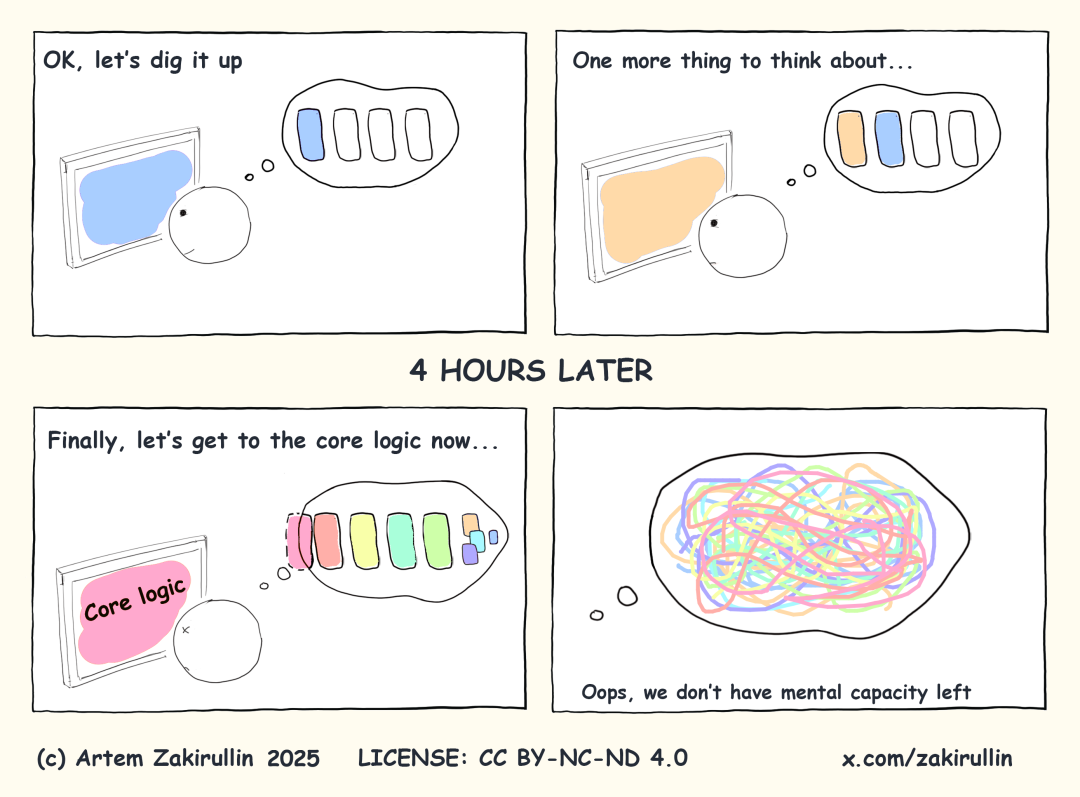
在我们的项目中,应当尽可能地降低认知负荷。
PART 03:认知负荷的类型
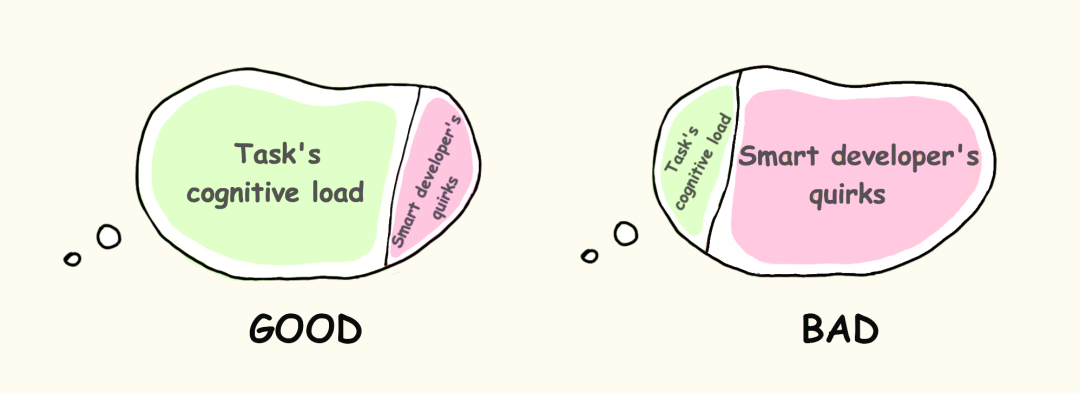
内在负荷(Intrinsic):由任务本身的难度所决定,无法削减。这是软件开发的核心所在。
无关负荷(Extraneous):由信息的呈现方式导致,与任务本身无直接关联(例如开发者个人的“聪明技巧”)。这部分负荷可以大幅削减。我们将重点关注这类认知负荷。
PART 04:复杂条件语句
if val > someConstant // +
&& (condition2 || condition3) // +++, 前一个条件必须为真,condition2或condition3中至少有一个为真
&& (condition4 && !condition5) { // , 到这里就已经开始混乱了
...
}引入具有清晰含义的中间变量:
isValid = val > someConstant
isAllowed = condition2 || condition3
isSecure = condition4 && !condition5
// , 我们不必再记住复杂条件,而是用描述性变量表示
if isValid && isAllowed && isSecure {
...
}PART 05:嵌套 if 语句
if isValid { // +, 好的,嵌套代码只针对有效输入
if isSecure { // ++, 仅对既有效又安全的输入进行操作
stuff // +++
}
}对比“提前返回”
if !isValid
return
if !isSecure
return
// , 我们无需关心中途的返回逻辑,能走到这里说明输入都没问题
stuff // +这样一来,我们只需关注理想路径,工作记忆也无需负担各种前置条件。
PART 06:继承的“噩梦”
我们需要为管理员用户修改一些功能:
AdminController extends UserController extends GuestController extends BaseController哦,部分功能在 BaseController 中,让我们先看看: +
基础的角色机制在 GuestController 里实现: ++
在 UserController 中又进行了一部分修改: +++
最后,我们来到了 AdminController ,开始编写代码吧! ++++
哦,等等,还有 SuperuserController 继承自 AdminController 。如果我们改动 AdminController ,可能会破坏子类的逻辑,所以我们得先去看看 SuperuserController :
尽量优先使用组合而非继承。这方面的资料非常多,这里不再展开。
PART 07:过多的小方法、小类或小模块
- 在这里,方法、类和模块是可互换的概念。
“方法应少于 15 行”或者“类要尽量精简”之类的信条,在某些场景下并不一定正确。
深层模块:接口简单,但内部功能复杂
浅层模块:提供的功能很少,但接口却相对复杂
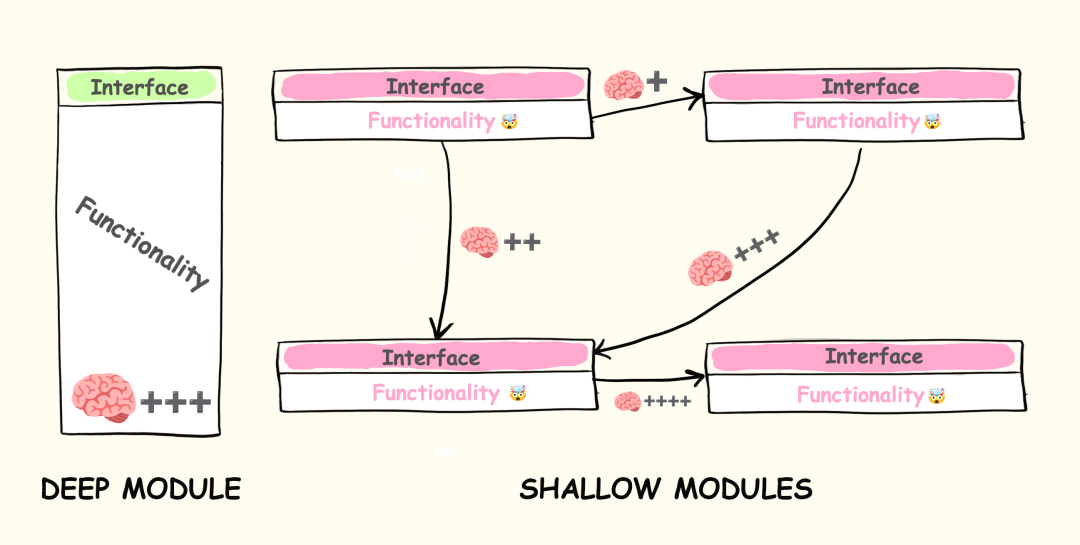
过多的浅层模块会让整个项目难以理解。我们既要记住每个模块的职责,还要搞清它们之间的交互关系。要弄明白一个浅层模块的作用,往往不得不先查看与之相关的所有其他模块。
- 信息隐藏至关重要,而浅层模块并不能隐藏足够多的复杂性。
我有两个业余项目,代码量都在 5000 行左右。第一个项目有 80 个“浅层类”,第二个只有 7 个“深层类”。这两个项目我都搁置了一年半没维护。
当我重新开始维护时,发现第一个项目里 80 个类之间的相互关系非常难理清;在开始写代码之前,我得先重新建立庞大的认知负荷。相比之下,第二个项目因为只有少数几个深层类、接口也很简洁,所以我很快就能上手。
- “The best components are those that provide powerful functionality yet have a simple interface.” —— John K. Ousterhout
UNIX I/O 的接口非常简单,只有以下五个基础调用:
open(path, flags, permissions)
read(fd, buffer, count)
write(fd, buffer, count)
lseek(fd, offset, referencePosition)
close(fd)在现代操作系统中,这些接口的具体实现可能有数十万行代码,但大量复杂度都被封装在底层。由于对外接口简洁,使用起来依然很方便。
- 以上这个深层模块的例子,摘自 John K. Ousterhout 的《软件设计哲学》。
PART 08:过多的浅层微服务
“浅深模块”的原则与规模无关,同样适用于微服务架构。过多的浅层微服务于事无补——业界正逐渐走向某种“宏服务”形态,即不那么浅薄(更“深”)的微服务。
我曾为一家初创公司提供咨询服务,该公司一个 5 人团队居然引入了 17 个(!)微服务。结果进度整整落后了 10 个月,离上线遥遥无期。每个新需求都要改 4 个或更多微服务,集成方面的排查难度急剧上升。上市时间和认知负荷都高得让人难以接受。
这真是应对新系统不确定性的正确方式吗?在早期阶段就划分出完全合理的逻辑边界,本来就非常困难。关键在于在自己还能负责任地等待的范围内,尽可能晚地做出决定,因为那时你掌握的信息最为充分。一旦过早引入网络层,我们的设计决策就从一开始就变得难以回退。而他们给出的唯一理由是:“FAANG 公司已经证明了微服务很有效。”拜托,别再好高骛远了。
一个经过精心设计、拥有真正隔离模块的单体应用,通常比一堆微服务要灵活得多,而且维护的认知负荷也更低。只有在“必须要分别部署”成为关键需求时(例如开发团队规模急剧扩大),才应考虑在模块之间引入网络层,为后续的微服务演进做准备。
PART 09:功能丰富的编程语言
当我们喜欢的编程语言推出新特性时,我们总是兴奋不已,花时间学习并在此基础上编写代码。
如果语言功能太多,我们可能会花上半小时来折腾区区几行代码,只为了用某个新特性。这本身就有点浪费时间,而更糟糕的是,过段时间回头再看,你需要重新还原当初的思路!
“You not only have to understand this complicated program, you have to understand why a programmer decided this was the way to approach a problem from the features that are available.”
上述言论出自 Rob Pike 本人。
- 通过限制可选方案的数量来降低认知负荷。
只要不同特性之间相互正交,语言特性并无不妥。
PART 10:业务逻辑与 HTTP 状态码
后端返回:
401:JWT Token 过期
403:权限不足
418:用户被封禁
前端工程师利用后端 API 实现登录功能,他们需要在大脑里暂时记住:
401 is for expired jwt token // +, ok just temporary remember it
403 is for not enough access // ++
418 is for banned users // +++
前端开发者通常会在自己代码里做一个“状态码 -> 含义”的映射字典,以避免后续参与的同事重复背这些数字含义。
接着,QA 工程师会问:“我拿到了 403 状态,这到底是 Token 过期还是权限不足?”他们无法直接测试,因为必须先去记住或区分后端设置这些状态码的来龙去脉,才能理解测试结果。
为什么要让大家把这种自定义映射存在脑子里?更好的做法是将业务细节与 HTTP 协议本身分离,并在响应体中直接返回“自描述”的代码:
{
"code": "jwt_has_expired"
}前端的认知负荷: (无需背记状态含义)
QA 的认知负荷:
同理,数据库里或其他地方使用的各种数字状态码,也应该尽量改成自描述的字符串。我们早已不在 640K 内存时代,不必为那一点点内存做过度优化。
PART 11:分层架构
抽象本应隐藏复杂度,但在这种场景下却可能只是徒增间接层次。为了快速定位问题、搞清缺失点,你需要在各个调用间来回追踪。在这种高度解耦的多层架构里,要找到故障源往往需要进行指数级的额外追踪,而且这些零散的追踪步骤都会占用我们有限的工作记忆。
这种架构在直觉上或许说得通,但每次真正用到项目中往往弊大于利。最后,我们干脆全部放弃,回归经典的“依赖倒置原则”。无需学习什么“端口/适配器”术语,也不必添加那些水平分层的冗余抽象层,自然也就不会额外增加认知负荷。
如果你认为这些分层能让你快速替换数据库或其他依赖,那就大错特错了。更换存储会带来大量问题,而相信我们,对数据访问层进行抽象只是你最不需要担心的那一部分。抽象层顶多能为迁移节省约 10% 的时间(如果有的话),真正的麻烦在于数据模型不兼容、通信协议差异、分布式系统的复杂性和那些隐式接口。
我们曾做过一次存储迁移,花了将近 10 个月。旧系统是单线程的,事件按顺序发出,其他系统都依赖于这个顺序行为。但这个行为既不在 API 契约中,也没在代码里明示。新的分布式存储并不保证顺序,事件会乱序到达。我们只花了几个小时写了一个新的存储适配器,却用了接下来 10 个月来处理乱序事件等各种挑战。现在再说“分层有助于快速替换组件”,真是讽刺。
所以,如果这种分层架构无法在将来带来实际收益,为什么要为此付出高认知负荷的代价呢?
不要为了所谓的“架构美感”而额外添加抽象层。只有在确有实际需要扩展时,才增设相应的层。
抽象层并不是“免费午餐”,它们都会占用我们的有限工作记忆。
PART 12:一些示例
- 我们的架构是一个标准的 CRUD 应用:在 Postgres 之上搭建的 Python 单体应用
- Instagram 如何只用 3 名工程师就支撑起 1400 万用户?
- 我们曾经觉得“哇,这些人超聪明”的公司,大多后来都失败了
- 整个系统只靠一个函数串起来。如果想知道系统怎么运作,去看那一个函数就够了
这些架构乍看上去很“无聊”,但却容易理解。任何人都能轻松上手,不需要额外的脑力负担。
让初级开发者参与架构评审能帮助你发现哪些地方对大脑负担最大。
PART 13:在熟悉项目中的认知负荷
如果你已经把项目的各种心智模型内化到长期记忆中,你就不会再觉得有多大认知负荷。
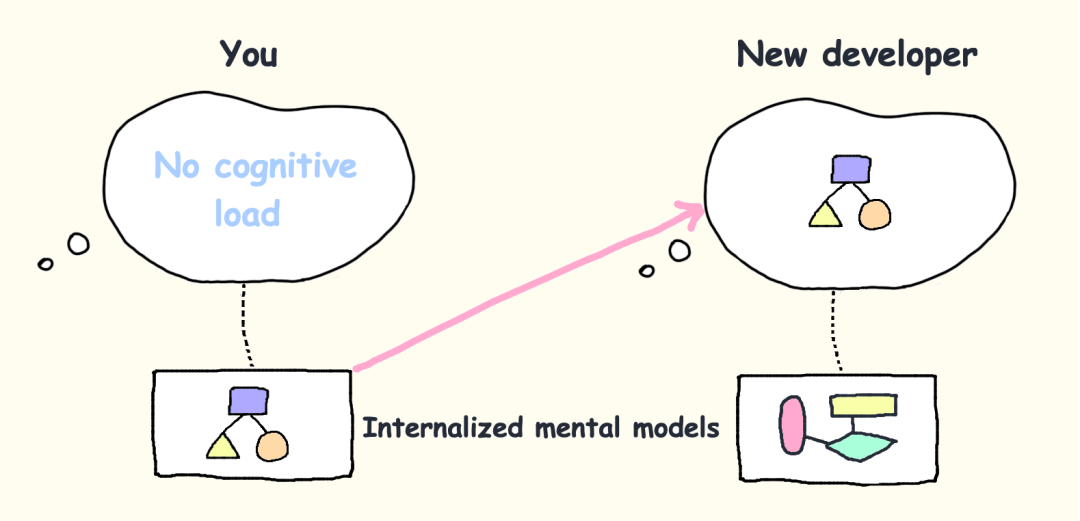
心智模型越多,新的开发者就需要花更久时间才能做出贡献。
当有新人加入项目时,可以试着观察他们的困惑程度(结对编程或许有助于这一点)。如果他们持续困惑超过 40 分钟,就说明代码还有改进空间。
如果能有效降低认知负荷,新人可能在入职后的头几个小时内就能为代码库做出贡献。
PART 14:结论
想象一下,如果我们在第二章的推断其实是错的,那么我们刚刚否定的那个结论,以及之前章节中被视为有效的结论,都可能是错的。
你感受到了吗?你需要到处翻找文章内容才能理解这段话(“浅层模块”的典型体现!),而这段话本身也很难懂。我们其实是在你的脑海中凭空制造了额外的认知负荷。千万别在团队里这样折磨同事。
我们应该尽量减少所有超出工作本身所必需的认知负荷。
以上内容翻译自 Artem Zakirullin 的《Cognitive load is what matters》,如需原文,请与我们联系。

WF Research 是以第一性原理为基础的专业顾问服务机构,欢迎关注和留言!
微信号:Alexqjl


